最近のCPUの仕組みを簡単に解説
最近はソフトウェアのライセンス数を数える時もCPUのコア数を数えなければならない。
パソコン選びをする時も、CPUのコア数以外にスレッド数やら仮想コア・論理コアなどの数値があって、IT素人さんだけではなく新人技術者でも良く分からないのではないかと思う。
この記事では、出来るだけIT素人さんでも理解できるように配慮して、CPUのマルチコアや仮想コア(スレッド・論理コア)の解説をしたいと思う。
詳しいところまで説明してみたので、長い説明になっている点は、ご了承いただきたい。
まずは、基礎から解説する。
簡単なコンピュータの構造とCPU
情報処理技術者試験の基礎だが、コンピュータのハードウェアは大きく分けて五種類の装置からできている。
「入力装置」「出力装置」「記憶装置」「演算装置」「制御装置」の五つである。
これらを「コンピュータの五大装置」と呼ばれる。
その内容は以下になる。
入力装置
パソコンの場合はキーボードとマウス。周辺機器にスキャナなど。
スマホやiPadなどのタブレットの場合は、タッチスクリーンのタッチ機構とカメラとマイクが、入力装置に該当する。
コンピュータに人間の指令や必要なデータを入力する装置だ。
名前のままの装置だ。
出力装置
パソコンの場合はディスプレイとスピーカー。周辺機器にプリンターなど。
スマホやiPadなどのタブレットの場合は、タッチスクリーンの表示スクリーン部分とスピーカーが、出力装置に該当する。
人間に情報を伝える装置だ。
入力装置と出力装置は、人間とコンピュータのインターフェイスとなる装置だ。
記憶装置
パソコンとスマホ共に、メインメモリとHDDやSSDなどのストレージが該当する。
入力装置から入力した情報を記憶しておく装置である。
メインメモリは電源を落とすと情報が消滅する揮発性記憶装置、HDDやSSDなどのストレージは電源を落としても情報を保持する不揮発性記憶装置となる。
演算装置
名前のように加算減算などの演算処理を行う装置である。
「同値」か、「大きいか」「小さいか」など条件演算も行う。
コンピュータでは負数に「ビット反転して1を足した値」である「二の補数」を使用して、加算演算だけで、減算も実施している。
乗算は「左ビットシフトすると2倍になる」性質を利用した左シフト演算により実施しており、除算もその逆で実施している。
左右の「余り」のビットを取る事もできる。
つまり、「加算」と「左シフト」と「右シフト」と「余りビットの取得」だけで四則演算処理を実現している。
他に論理演算として、AND(論理積)とOR(論理和)とXOR(排他的論理和)とNOT(否定)を演算する機構を持つ。
制御装置
現在のコンピュータはノイマン型コンピュータと言って、プログラム内蔵型コンピュータとして設計されている。
これは、記憶装置に順番に並んだ命令群を記憶しておき、制御装置が一つずつ命令を読み出して、演算装置に渡して、演算結果をまた記憶装置に保存するという処理を、命令の数だけ繰り返す方式である。
この一連の命令実行の繰り返しを実施しているのが制御装置である。
CPU
五大装置の中で、「演算装置」と「制御装置」と一部の高速アクセスが可能な「記憶装置」が、一つの半導体チップに実装された装置をCPU(Central Processing Unit)と呼ぶ。
日本語だと「中央処理装置」と呼ばれる。
「一部の高速アクセスが可能な記憶装置」はレジスタとキャッシュの二種類になる。メモリとは異なる。
レジスタは演算装置が直接アクセスするもので、「演算する値」や「アドレス値」が格納される。数個から数十個存在する。一つのサイズは32bitのCPUなら32bit、64bitのCPUなら64bitである。
キャッシュはメインメモリから一時的に半導体の中に少数のデータを読み込み編集する為に存在する高速記憶装置だ。速度の速い方からL1,L2,L3の三階層になっていることが多い。L3がメモリと直接読み書きし、L1の値をレジスタとの間で読み書きする。
IntelプロセッサやAMDやARMなどが、そのCPU製品となる。
マルチコア
CPUの廃熱問題
昔のCPUの開発競争を知っている人なら「クロック数」というモノをかなり意識してCPUを選択していたと思う。
「クロック数」は別名「動作周波数」と呼ばれ、CPUが1回の指示命令を実行することを1単位として、1秒間に何回指示命令を繰り返すかを示す値である。
「クロック数」が大きいほど1秒間に実行する指示命令の回数が多くなる。
つまり処理速度が速いことになる。
しかし、2003年ごろからCPUのクロック数を気にする人はいなくなった。
クロック数自体もあまり変わらなくなり、2GHzから3GHz程度で頭打ちとなっている。
この理由としてCPUの廃熱処理が限界に達したという事情がある。
CPUの電子回路はその電線の太さがナノレベルの、非常に細い回線に通電して電子回路を稼働させている。
通常の回線は電気抵抗があるため、通電すると発熱する。
CPUの場合、回線が細い為ある程度以上の発熱になると、容易に回線が溶けて切れてしまう。
クロック数を上げていくと、CPUの発熱量が大きくなる。
2003年ごろまでは、冷却能力を向上させることで、CPUの発熱量の増大に対処できた。
しかし、その後はこれ以上クロック数を増大させた場合に、予測される発熱を冷却する事は不可能な水準まで、クロック数を引き上げてしまった。
よって、現在の3GHz強程度がCPUの限界水準のクロック数となったということだ。
これが「CPUの廃熱問題」である。
廃熱能力の限界に到達したことにより、これまでのようにクロック数を増大させる事による高速化はできなくなった。
クロック限界
クロック数が5GHz以上の水準になると、一回のCPU指揮命令サイクルの時間が短くなりすぎる。
物理法則で電子の移動速度は一定なので、あまりサイクル時間が短くなりすぎると、電子が電子回路を一巡する前に、次のサイクルが始まってしまい電子回路が機能しなくなってしまう。
無理に冷却してクロック数を増大しても、その先にはこのクロック限界が待ち受けており、クロック数を増大させる事による高速化はできなくなる。
集積度の限界
CPUの半導体回路の集積度を上げていくと、電子回路の回線が細くなる。
その回線の幅が原子10万個を下回ってしまうと、その回線を流れる電子の数は1個程度になってしまい、0と1を識別するには少なすぎる。
最低でも2個の電子が流れないと「電子1個が0」「電子2個が1」という具合に二進法が表せなくなる。
絶対に無理なのか私にも分からないが、回線の幅に物理的限界が存在することは理解できると思う。
現在のCPUは既にその限界に近づいているそうだ。
集積度を上げることによる高速化も、そろそろ限界を迎えている。
マルチコアによる分散処理
CPUの廃熱能力の限界に達したからといって、CPUメーカーとしては高速化を諦めるわけにはいかない。
そこでクロック数増大とは異なる手段で高速化を目指し始めた。
その手段として選ばれた一つがマルチコア技術である。
マルチコアとは一つの半導体基板(ダイと呼ばれる)の上に、複数の演算装置を中心としたコア回路を配置したCPUの設計である。
簡単に言うと「一つのCPUの中に、複数の演算装置を配置したCPU」である。
制御装置は複数のコアへ処理を振り分けるので共有であり、CPU内の高速記憶装置(レジスタなど)はコアごとに独立しており、CPUキャッシュなどは共有である。
一つのコンピュータに複数のCPUを設置するマルチプロセッシングと考え方は同じである。
プログラムの命令を実行するとき、命令を複数のCPUに分散して実行させるため、処理速度が速くなる。
シングルタスク処理では分散処理はできないので高速化できないが、マルチタスクやマルチスレッド処理なら、分散できるので処理速度が高速化する。
マルチコアCPUは、一つの半導体回路に複数のCPUコアを配置しているので、命令の負荷分散処理が早くなる。
また、CPUの設置面積もCPUが一つだけなので、場所を取らない。小型化できる。
大半のOSはマルチタスク・マルチスレッド対応なので、マルチコア・プロセッサと相性が良い。
現在のパソコンやスマホのCPUは、ほとんどマルチコア・プロセッサとなっている。
物理コア
「物理コア」とは、このマルチコア・プロセッサの「CPUコア」のことである。
一つのCPUに複数の「物理コア」が存在する。
仮想コア
CISCとRISC
486DXまでのインテルプロセッサはCISC(シスク:Complex Instruction Set Computer)と呼ばれる開発手法で開発されていた。
その後、Pentiumプロセッサから現在までに開発されているCPUは全てRISC(リスク:Reduced Instruction Set Computer)という開発手法で開発されている。
インテルプロセッサはCISC命令が使用できるが、あれはプロセッサ内部でRISC命令に翻訳しながら実行している。
AMD,ARMのプロセッサも現在は全てRISCプロセッサである。
CISCプロセッサ
CISCプロセッサというのはアセンブラ命令でプログラムを組んだとき、比較的コードを書きやすいように、一つ一つのアセンブラ命令を高機能に設計したCPUだ。
アセンブラとは数値の機械語を、人間が理解しやすいニーモニックという単語に置き換えた、コンパイラのような開発ツールである。
ニーモニックでコーディングして、アセンブラで機械語に変換する。
アセンブラ・ニーモニックと機械語は、ほぼ一対一で対応すると考えて欲しい。マクロアセンブラは除く。
CISCプロセッサのアセンブラ・プログラムは、アセンブラにしては比較的短いコードで多くのことができる。
人間のプログラマーにとっては扱い安いCPUになる。
その代わりCPUのアーキテクチャ(設計・構造などの意味)は非常に複雑になり、CPUそのものの開発は困難になる。
CPUの集積度が増し、設計が複雑になってきたことにより、CISCプロセッサの開発は困難になり、高速化にも不向きな設計の為、後に採用されなくなった。
RISCプロセッサ
RISCプロセッサというのは、アセンブラ命令に必要最小限の単純な命令しか用意されず、全ての命令長が固定サイズ(固定バイト長)になるように設計された、プロセッサの開発手法である。
アセンブラ命令でプログラムをコーディングとき、高機能な命令は存在せず、全てプログラマーが必要な機能を基本からコーディングしなければならない。
アセンブラのプログラマーにとっては不便で扱い難いCPUとなる。
その代わり、CPUの設計は単純になり、CPUそのものの開発はやり易くなる。
また、全ての命令長が固定サイズなので、後で説明するパイプライン制御などの高速化手法を採用する事が可能で、CPUの高速化が実現し易いという大きなメリットがある。
CISCが採用されていた時代は、まだコンピュータの高級言語コンパイラなどの性能が不十分で、人間のプログラマーがソフトウェア細部のコードを一部アセンブラで書いていたため、命令が高機能のCISCプロセッサは便利なCPUだった。
しかし、高級言語やコンパイラの最適化性能などが向上してくると、人間がアセンブラでプログラミングするより、高級言語コンパイラの最適化されたプログラムの方が高速で効率が良くなり、アセンブラ自体が使われなくなっていった。
必然的に開発が困難で、高速化に難のあるCISCは採用されなくなり、多くのプロセッサは速度競争もあってRISC方式を採用するようになった。
パイプライン制御
CPUが命令を実行するときには、その仕組みから決まった手順がある。
簡単に抽象化した説明では、CPUの1命令の実行手順は以下の4手順に分かれる。
(IF)命令フェッチ(命令を読んで来る)
(ID)命令デコード(命令を解読する)とレジスタ・フェッチ(パラメータをレジスタへ読んで来る)
(EX)実行(読み込んだ命令とパラメータを実行する)
(RS)レジスタへのライトバック(実行結果を指定レジスタへ書き込む)
電子回路としてIF,ID,EX,RSはそれぞれ異なる独立した回路が実装されている。
回路の機能と役割が、それぞれ異なるので当然のことである。
それぞれの回路が独立しているなら、それぞれが別々に機能を並列に独立実行することも可能である。
そこで高速化の為に、「4手順を同時に1手順ずつ遅らせて同時に実行する」という制御をRISCプロセッサは採用している。
この制御を、「パイプライン制御」と呼ぶ。
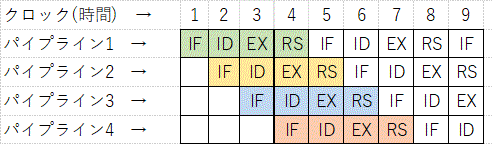
4つの命令を並列実行する様子を、図で表すと以下のようになる。
最初のパイプライン1のIFを実行し終わった段階(クロック)でIF回路は空いている。
そこにパイプライン2のIFを実行させることができる。
その時、パイプライン1では次のID回路を実行することができる。
この方式をIF,ID,EX,RSの4手順すべてで実行可能である。
パイプライン1のIDを実行し終わった段階でID回路は空いている。
そこにパイプライン2のIDを実行させることができる。
その時、パイプライン1では次のEX回路を実行することができる。
パイプライン1のEXを実行し終わった段階でEX回路は空いている。
そこにパイプライン2のEXを実行させることができる。
その時、パイプライン1では次のRS回路を実行することができる。
といった具合にである。
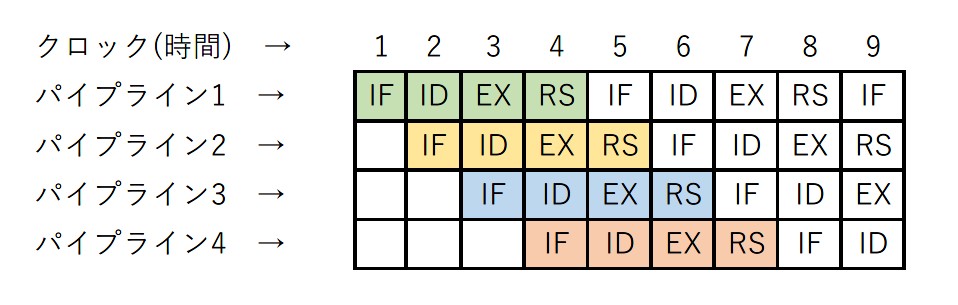
応用情報処理技術者試験や代表的パイプライン制御の説明では以下のように6手順で説明する。
基本的な考え方は同じだ。細かく切り分けただけだ。

RISCプロセッサでは、このパイプライン制御により、6つの命令を1手順(1クロック)遅れで、同時に実行することができる。
これによりCISCではできない高速化を実現している。
RISC命令サンプル
rd,rs1,rs2,rs3,rs4 は全てレジスタである。名称は仮名だ。
以下は「メモリの相対アドレス100番地の値と、同200番地の値の和をとり、同500番地へ書き込む」というRISC命令のサンプルだ。
これはニーモニックになる。
アセンブラによって数値の機械語(マシン語)に翻訳される。
lw rs3,rs1,100 【メモリの「rs1の値+100」番地の値をr3に読み込む】
lw rs4,rs1,200 【メモリの「rs1の値+200」番地の値をr4に読み込む】
add rd,rs3,rs4 【rs3とrs4の値の和をrdへ書き込む】
sw rd,rs2,500 【rdの値をメモリの「rs2の値+500」番地へ書き込む】
命令の長さ(バイト長)は全て同じでレジスタのサイズになる。
32bitのCPUなら32bit長、64bitなら64bit長になる。
例: add rd,rs3,rs4
機能【rs3とrs4の値の和をrdへ書き込む】
IF: CPUのプログラムカウンターの示すメモリ上の命令を、命令レジスタへ読み込む。
ID: add 命令を解読する。
OA: アドレス計算は特に何もしない。
OF: メモリアドレス値の関連付けも特に必要無い。
EX: rs3レジスタの値とts4レジスタの値の和を算出する。
RS: 計算結果を rdレジスタへ書き込む。
パイプラインを簡単に解説
一つの命令の処理はデコード、フェッチ、エクスキュート、ライトバックに分かれる。
デコードは命令(opcode:オペコード)の識別と、命令に合った読み方でパラメーターを選択する。
フェッチは、命令なら「命令レジスタへの命令の読み込み」、アドレスなら「アドレス修飾用レジスタへのアドレス値の書き込み」を意味する。
エクスキュートは、命令レジスタとアドレス修飾用レジスタの内容を実行する。
ライトバックは、エクスキュートの結果を、命令で指定するレジスタへ書き込む。
命令の種類により、IF,ID,OA,OF,EX,RS の手順の一部が空白になる場合もある。
この場合は特に何もしない。
一つの物理コアに、IF,ID,OA,OF,EX,RS の回路はそれぞれ一つしかない。
物理コアの数だけ、これらの回路が存在する。
マルチコアでは、コアごとにパイプライン制御が別々に実行される。
HTT:ハイパースレッディング・テクノロジー
物理コアをマルチスレッド化するテクノロジー。
使用されていない演算回路
CPUの演算装置には、整数加減算・シフト演算・論理演算などいくつかの定まった機能を持つ演算回路が組み込まれている。
ざっくりと演算回路のカテゴリを一覧すると以下のようになる。
(1)整数の加減算
(2)シフト演算(左シフトで値は二倍に、算術右シフトで二分の一に。他に論理シフトなど)
(3)論理演算(AND,OR,XOR)
(4)比較判定(大小比較の判定)
(5)ロード(メモリからレジスタへコピー)
(6)ストア(レジスタからメモリへコピー)・
(7)実数四則演算(実数の計算は整数とは全く異なる)
(8)条件分岐(一致・不一致の条件によってジャンプする)
「整数の加減算」の中に加算回路・減算回路が存在する。
「論理演算」の中にも論理積回路(AND)・論理和回路(OR)・排他的論理和回路(XOR)がある。
それぞれの演算回路カテゴリの中でさらに詳細に、具体的な機能に対応したいくつもの演算回路がある。
パイプラインで解説した、一つの命令サイクルで実行(EX:エクスキュート)する演算回路は一つだけである。
整数の加算回路を実行しているとき、他のシフト演算や実数の加算・減算・乗算・除算や比較判定回路などは、使用されていない。
左シフト演算回路を実行しているときも、加算回路など他の演算回路は使用されていない。
つまり演算回路は、どれか一つの演算回路を使用しているとき、他の演算回路は空いている。演算装置は常に一部分しか使用されていない。
これは計算機資源として勿体ないことだ。
そこで、この空いている演算回路を使用して、計算速度を向上させるテクノロジーが生み出された。
二つの命令サイクルを同時に動かす
そのテクノロジーでは、使用していない演算回路を活用する為に、プロセッサの物理コアの中の、プログラムカウンター・スタックポインター・汎用レジスタなど命令サイクル実行に必要なコア内の記憶装置を、それぞれ全てコア内に二重に設置し、一つの物理コアで二つの命令サイクルを同時並列に実行できるようにしている。
制御装置やCPU内のキャッシュ(高速記憶装置)などは、共有している。
このテクノロジーの名をハイパースレッディング・テクノロジー(Hyper-Threading Technology : HTT)と呼ぶ。
ハイパースレッディングはインテルの固有技術の名称で、AMDではサイマルテイニアス・マルチスレッディング(Simultaneous Multi-Threading : SMT)という呼称が使用されている。
基本的に両者は同じような技術である。
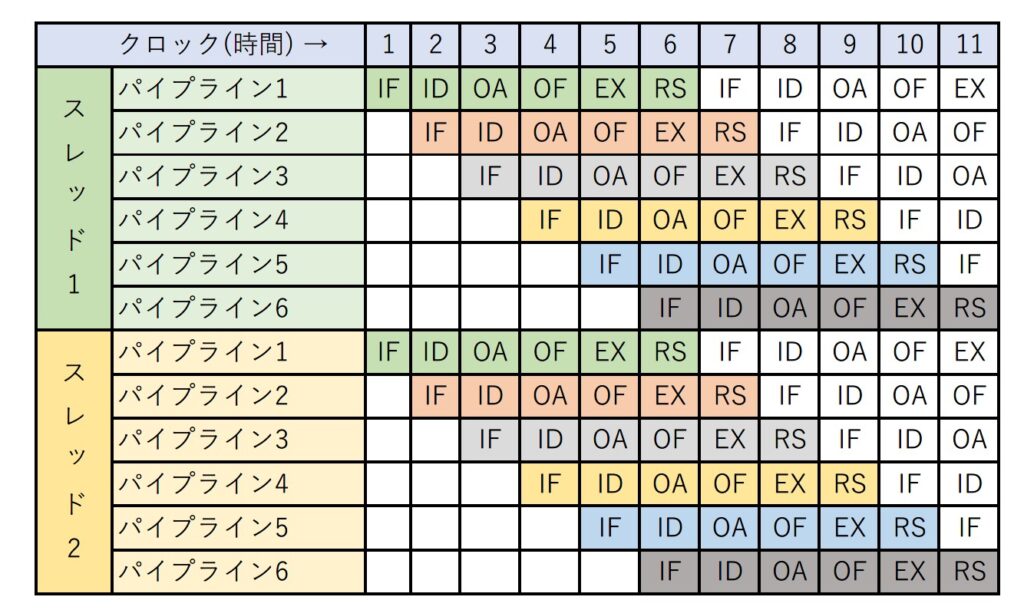
パイプライン制御では6つの手順の命令サイクルを1手順ずつ遅らせることで、同時に6つの命令サイクルを動かしているが、1クロックで稼働しているEX:エクスキューズは常に一つだけである。
ハイパースレッディング・テクノロジーでは、1クロックでEX:エクスキューズが二つ同時に稼働する。
もちろん6つの手順 IF,ID,OA,OF,EX,RS が全て同時に二つ稼働する。
レジスタ群が二重に存在し、二つの命令サイクルのレジスタ群が独立しているので、それぞれ同時並行で実行可能となる。
但し、同じ演算回路を何度も繰り返す場合は、一つのEX:エクスキューズしか稼働しない。
例えば多数の商品の合計値を求めるときなど、整数の加算命令ばかり連続で実行するかも知れない。
この場合は整数の加算回路は物理コアに一つしかないので、一つの命令しか実行できない。
一つしか無い整数加算回路を同時に二つ実行することはできない。
そのため、同時に二つの命令サイクルを実行できると言っても、マルチコアのように完全に二つの命令サイクルを同時実行できるわけではなく、プログラムの内容によっては一つしか実行できない場合もある。
だから単純に計算速度が二倍になるわけではない。
インテルの説明では、5%の演算装置の拡充で、15%から30%ほどの性能向上が得られるという。
ハイパースレッディング・テクノロジーはRICSプロセッサの技術なので、パイプライン制御も同時に実装できる。
現代のプロセッサは全て、ハイパースレッディング・テクノロジーにより、二つのパイプライン制御を同時実行している。
以下はイメージ図だ。
仮想コア
ハイパースレッディング・テクノロジーにより、物理コアは二つの命令を同時に実行できることになる。
プログラムでは、それぞれのスレッドに対して、別々の命令を与えて個々に独立して実行させることになる。
これは、外から見るとコアが二つあるように見える。
この物理コアの中にある「二つあるように見えるコア」のことを「仮想コア」と呼ぶ。
IntelのCPU製品の「○コア○スレッド」という表記の「○コア」というのが「物理コア」のことであり、「○スレッド」というのが「仮想コア」の事である。
仮想コアは「論理コア」とか「スレッド」「論理プロセッサ」などとも呼ばれる。
Intel Coreシリーズの物理コアと仮想コア(スレッド)数の例
(世代やノート用・サーバー用などで異なる)
Core i9 → 10コア 20スレッド
Core i7 → 8コア 16スレッド
Core i5 → 6コア 12スレッド
Core i3 → 4コア 8スレッド
終わりに
解説を読んで気がついた人もいるかも知れないが、CPUの性能向上は限界に近づいている。
現代のCPUは極限までクロック数を引き上げ頭打ちになっており、半導体集積度の向上も近い内に限界に達する。
高速化も現状ではコア数を増やすしかない。
しかし、スーパーコンピュータの専門家の解説などを見て回ると、CPUのコア数は最大で32コアまでが限界のようで、32コアを上回ると有意な性能向上は見られないという話も聞く。
コアの数が増えると負荷分散の負担が増えるからだろう。
本当かどうかは分からないが、それが事実なら、そろそろマルチコアによるCPU高速化も限界を迎えることになる。
10年から15年ぐらいで、CPU性能向上は限界に達するのかも知れない。
既にパソコンのCPUはそれほど早くなっていないように見える。
SSD化や、メモリやストレージの入出力速度の向上などにより高速化しているように見える。
こちらもすぐに限界に達するだろう。
量子コンピュータなど革新的なコンピュータが登場すれば、また別だが、現在技術の延長線上の高速化は将来の限界が見えているようだ。
どこかの一級技術者らしき人が雑誌か何かでこれについてコメントしていたが、これまではハードウェアの高速化にソフトウェアの高速化が依存していたが、今後はハードウェアの高速化は期待できず、将来はマルチコアやクラウドなどで、沢山のハードウェアを使ってソフトウェアで性能向上を目指すようになるのではないか、と話していた。
実際に現在その兆候が見え始めている。
スマホの普及で人間が使用するIT機器の種類も数も増えているし、クラウドなどサーバー側の機器も大幅に増加した。
IoTなども後に控えていて、これらを制御する為にエッジコンピューティングが必須と言われている。
5Gなど通信速度も向上していて分散処理がやりやすくなってきている。
今後のソフトウェアの高速化は、どれだけ多くのコンピュータに効率良く分散情報処理できるかに掛かっているのかも知れない。

