
クライアントからの接続先インスタンスの解説
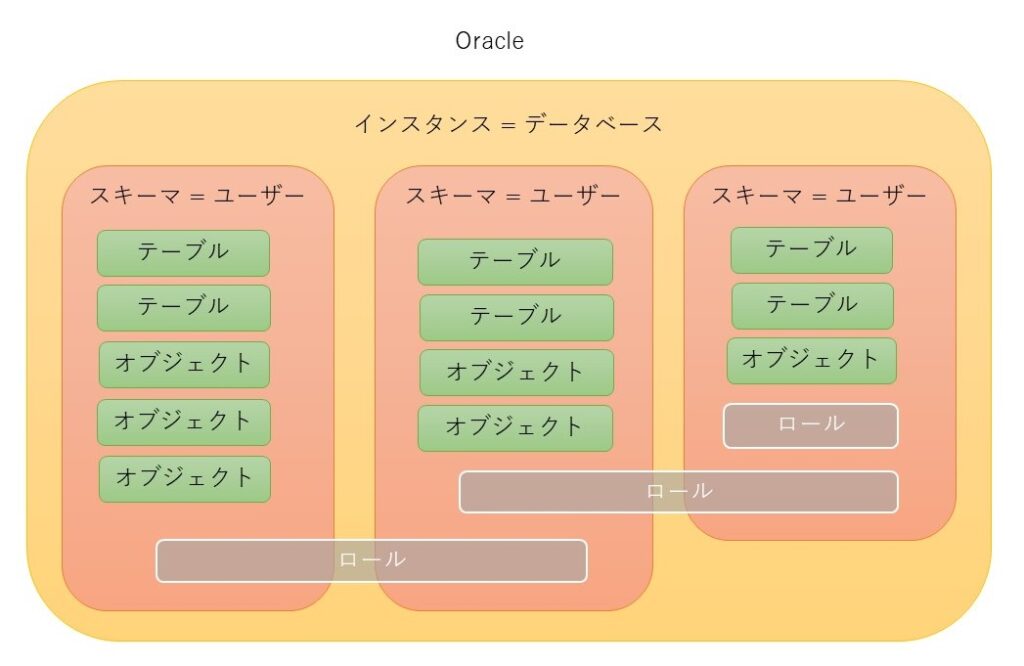
Oracleは元々一つのインスタンスに一つのデータベースを有するDBMSだった。
だからクライアントツールやアプリから接続する場合、インスタンスへの接続とデータベースへの接続は同義である。
しかしOracle12cからマルチテナント機能が導入された。
マルチテナントは、一つのインスタンスに複数のデータベースを保有できる機能だ。
一つのOracleインスタンスの中に、CDB(コンテナ・データベース)一つに、複数のPDB(プラガブル・データベース)を持つ。
CDBは管理用のデータベースで、ユーザーやアプリが主に使用するデータベースはPDBである。
クライアントツールからCDBとPDBへは、まるで独立したインスタンスのように接続する。
PDBの数だけインスタンスが存在するかのように見えるが、Oracleのインスタンスは一つだけである。
一つのポート番号で全てのPDBとCDBに接続できる。
マルチテナントは、旧バージョンとの互換性を維持するため、インスタンス接続とデータベース接続を同じにする仕様にできている。
分かりにくいと思うが、強いて言うならインスタンスの中にまたインスタンスがあるように見える仕様になっている。
実際はポート番号は一つしか使わないので、インスタンスは一つだ。
しかし、PDBのインスタンスはCDBとは別に、起動終了を管理する必要がある。
インスタンス内部がどのように作られているかは知らない。マルチスレッドかも知れない。
SYSとSYSTEMの特権ユーザーでログインすると、CDBに接続する。
PDBへ特権ユーザーで接続したいときは、接続先のPDBにセッションを切り替える。データベースを切り替えるようになっていないのが他のDBMSと違う。
例えば、SQL Serverの場合は、異なるデータベースの内容をSELECT文で直接参照できるが、Oracleの場合はできない。接続先PDBのセッションを切り替えなければ、見る事すらできない。
Oracleは12cからマルチテナント機能を導入していて、旧バージョンと互換性を維持しているので、このような振る舞いになるのだろうと思う。
PDBをメインにアクセスする権限を与えられたユーザーでログインすると、PDBのセッションに繋がる。
通称としてOracleのインスタンス名のことをSIDと呼ぶ。
クライアントツール
コマンドラインツール
sqlplus
GUIツール
SQL Developer
インスタンスへの接続・終了方法
コマンドラインツール
コマンドのパラメーターは以下の名称で表記する。
username = ユーザー名
password = パスワード
hostname = Oracleサーバーの名称
orcl = SID名称
pdbname = PDBの名称
インスタンスへ接続する
特権ユーザーSYSで接続する場合は、末尾に権限を付けて、
sqlplus / as sysdba
とする。
リモートPCからSYSログインする場合は、以下のようにホスト名とSIDも指定する。
sqlplus sys/password@hostname/orcl as sysdba
リスナーが起動していないと、外部から接続することはできない。
SYSでログインした場合は、CDB(コンテナ・データベース)に接続する。
特権ユーザーSYSTEMで接続する場合は、末尾に権限は必要無い。
sqlplus system/password@hostname/orcl
SYSTEMでログインした場合は、CDB(コンテナ・データベース)に接続する。
起動方法
接続したとき、OracleインスタンスやPDBインスタンスが起動していなかった場合は起動しなければ使用できない。
起動するには、sqlplusでSYSでログインする。通常Oracleサーバー上で直接ログインする。
(注意点として、UNIX系のシェルは英字の大文字と小文字を区別するが、sqlplus内部では、区別しない。設定で変更可能なのでデータベース管理者に確認すること)
sqlplus / as sysdba
以下のどちらかの命令でOracleインスタンスが起動してCDBがオープンする。
STARTUP OPEN
または、
ALTER DATABASE OPEN;
PDBインスタンスは別に起動しなければならない。
以下の命令で起動できる。
ALTER PLUGGABLE DATABASE pdbname OPEN;
リスナーが起動していなければ、サーバーのシェルから lsnrctlコマンドでリスナーも起動する。
まず、リスナーの動作状態を確認する。
lsnrctl status
起動していなければ、リスナーを起動する。
lsnrctl start
終了方法
PDBインスタンスを終了する命令。
ALTER PLUGGABLE DATABASE pdbname CLOSE IMMEDIATE;
接続をPDBからCDBに切り替える。
ALTER SESSION SET CONTAINER = CDB$ROOT;
Oracleインスタンスを終了する命令。
SHUTDOWN IMMEDIATE
sqlplusで接続したセッションは以下の命令で終了できる。
EXIT
リスナーを終了する。
lsnrctl stop
データベースへの接続や切替
先に説明したようにOracleでは、CDB・PDBごとに仮想的インスタンスがあり、それにクライアントから接続する。
インスタンス指定は、@の後ろにホスト名とSID名かPDB名を指定する。
データベースへ接続する
CDBへ接続する場合はSIDを指定する。
sqlplus username/password@hostname/orcl
PDBへ直接接続する場合はPDB名を指定する。
sqlplus username/password@hostname/pdbname
PDBへ接続するユーザーは、PDBへのアクセス権限を有していなければならない。
データベースを切替える
正確には接続するPDBインスタンスのセッションを切り替える。
既にログインしているものとする。
ALTER SESSION SET CONTAINER = pdbname;
現在の確認
現在の状態やオブジェクトを確認するときは、Oracle内部でオブジェクト情報を閲覧できるデータディクショナリビューを使用する。
データディクショナリの内容を閲覧するには、以下のSELECT文を使用する。
SELECT TABLE_NAME FROM DICTIONARY;
データディクショナリビューには、頭文字別に以下の3種類ある。
DBA_* データベース全ての情報を閲覧する。特権ユーザーしか参照できない。
ALL_* 自分がアクセスできるオブジェクトのみ閲覧する。
USER_* 自分が所有しているオブジェクトのみ閲覧する。
以下で解説する基本操作も、DBA_* 参照するものは、特権ユーザーしか使用できない。
また、SHOWコマンドも一部は、特権ユーザーでしか使用できない。
現在接続しているデータベースを確認する
特権ユーザー(sys, system)しか以下の確認はできない。
現在のデータベースを確認する
SELECT NAME FROM V$DATABASE;
現在のPDBを確認する
SELECT NAME FROM V$PDBS;
PDBの一覧を得る
SHOW PDBS;
現在のスキーマを確認する
Oracleでは、スキーマとユーザーは同じ。一般ユーザーでも確認できる。
SHOW USER;
現在のユーザーを確認する
Oracleでは、スキーマとユーザーは同じ。一般ユーザーでも確認できる。
SHOW USER;
一覧の表示
データベース一覧の表示
PDBの一覧を得る。特権ユーザーのみ実行可能。
SHOW PDBS;
スキーマ一覧の表示
Oracleでは、スキーマとユーザーは同じです。
SELECT USERNAME FROM DBA_USERS;
SELECT USERNAME FROM ALL_USERS;
SELECT USERNAME FROM USER_USERS;
DESC USER_USERS などで、ビューの必要な項目を確認できる。
テーブル一覧の表示
SELECT TABLE_NAME FROM DBA_TABLES;
SELECT TABLE_NAME FROM ALL_TABLES;
SELECT TABLE_NAME FROM USER_TABLES;
DESC USER_TABLES などで、ビューの必要な項目を確認できる。
オブジェクト一覧の表示
SELECT OBJECT_NAME FROM DBA_OBJECTS;
SELECT OBJECT_NAME FROM ALL_OBJECTS;
SELECT OBJECT_NAME FROM USER_OBJECTS;
DESC USER_OBJECTS などで、ビューの必要な項目を確認できる。
自分のオブジェクトだけ表示する
SELECT *
FROM USER_OBJECTS;
WHERE OBJECT_TYPE = 'オブジェクトタイプ名'
他のユーザーのオブジェクトだけ表示する
SELECT *
FROM DBA_OBJECTS
WHERE OWNER = 'ユーザー名'
AND OBJECT_TYPE = 'オブジェクトタイプ名'
オブジェクトタイプ名
TABLE / INDEX / VIEW / FUNCTION / PROCEDURE / TRIGGER / PACKAGE / PACKAGE BODY / SEQUENCE / SYNONYM / DATABASE LINK
ユーザー一覧の表示
Oracleでは、スキーマとユーザーは同じです。
SELECT USERNAME FROM DBA_USERS;
SELECT USERNAME FROM ALL_USERS;
SELECT USERNAME FROM USER_USERS;
ロール一覧の表示
SELECT USERNAME FROM DBA_ROLES;
SELECT USERNAME FROM ALL_ROLES;
SELECT USERNAME FROM USER_ROLES;
個別情報の表示
テーブルのレイアウトを表示する
DESC テーブル名 ;
DESCRIBE テーブル名 ;
ユーザーのロールを表示する
SELECT * FROM DBA_ROLE_PRIVS WHERE GRANTEE = 'ユーザー名';
SELECT * FROM USER_ROLE_PRIVS WHERE USERNAME = 'ユーザー名';
自分のロールを表示する
SELECT * FROM SESSION_ROLES;
ファイル入出力
SELECT結果をテキストファイルへエクスポートする
ファイルへのエクスポートは、SQLPLUS内のSPOOLコマンドにより、出力先を指定してSELECT文を実行することで行う。
事前の準備として出力形式を指定する必要がある。
-- コンソールメッセージを非表示にする
SET ECHO OFF
-- 1行に出力するバイト数
SET LINESIZE 32767
-- 1ページの行数(無制限にする)
SET PAGESIZE 0
-- メッセージを非表示にする
SET FEEDBACK OFF
-- 区切り文字をカンマに指定する(CSVファイル出力)
SET COLSEP ','
-- 各行の右端にあるスペースを削除する
SET TRIMSPOOL ON
出力先をファイルに切り替える。(ファイルのフルパスを指定する)
SPOOL C:\output.csv
この状態で、SELECT文を実行すると、結果をファイルに出力する。
出力が終わったら、元に戻す。
SPOOL OFF
テキストファイルをインポートする
インポート手段は二つある。
Oracleサーバー機の中で、テキストをインポートする方法と、クライアント機からテキストをサーバーに送信するインポートの二つである。
サーバー機内でのインポート
UTL_FILEパッケージのGET_LINE関数を使用する。
–参照ファイルの置き場所を、directory オブジェクトで定義する。
Create directory EXPORT_DIR as '/home/oracle'
–特権ユーザー以外を使用する場合は、権限をユーザーに与える。
grant read on directory EXPORT_DIR to ユーザー;
–特権ユーザーでプロシージャを作る。(権限があれば、他のユーザーでもよい)
— 以下は import_user.csv ファイルを読み込み表示する処理。
CREATE OR REPLACE PROCEDURE read_users
AS
IN_HANDLE UTL_FILE.FILE_TYPE;
BUF VARCHAR2(2048);
BEGIN
IN_HANDLE := UTL_FILE.FOPEN('EXPORT_DIR', 'import_user.csv' , 'R', 2048 );
LOOP
BEGIN
UTL_FILE.GET_LINE(IN_HANDLE, BUF);
DBMS_OUTPUT.PUT_LINE(BUF);
EXCEPTION
WHEN NO_DATA_FOUND THEN EXIT;
END;
END LOOP;
UTL_FILE.FCLOSE(IN_HANDLE);
END;
/
--実行する
SET SERVEROUTPUT ON;
EXECUTE read_users;
クライアント機からのインポート
クライアント端末からCSVファイルなどテキストファイルのデータをインポートするには、SQL*Loader というOracle標準ツールを使用する。
SQL*Loader はOracle標準コマンドツールで、sqlldr というコマンド名になる。
まず、コントロールファイルを作成して、ロード方法を指定する。
拡張子は .ctl である。
仮に取り込みテーブルが loaddata1 、csvファイルが import.csv とする。
import.ctl ファイル
LOAD DATA
CHARACTERSET UTF8
INFILE 'import.csv' -- データファイルのパス
APPEND -- 既存のデータを保持したまま追加
INTO TABLE loaddata -- データを挿入するテーブル名
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' -- フィールドはカンマで区切られている
TRAILING NULLCOLS -- 列がデータファイル中にない場合、NULLとして扱う
(
column1, -- loaddataテーブルの列と対応するデータファイルの列を指定
column2,
column3
)
csvファイルを用意して、以下のコマンドで、ロードを開始する。
sqlldr ユーザー名/パスワード@サーバー名/データベース名 control=import
整数型や日付型など様々な指定ができるが、実用的な使い方として、一度全部テキストカラムのロード専用のテーブルを作成して、CSVファイルをロードして、その後でロード専用テーブルから、目的のテーブルに insert select でデータ移行した方が良いと思う。
作成する
データベースを作成する
CREATE DATABASE で作成できるが、Oracleの場合、データベースとインスタンスは同義なので、データベースの作成は新たなインスタンスの作成を意味する。
通常は、他のDBMSのように手軽にSQLでデータベースを作成しない。
データベースとインスタンスの作成には、GUIツールの Database Configuration Assistant(DBCA)を使用することが多い。
手軽な作業ではないので、この記事では説明しない。
スキーマ(ユーザー)を作成する
Oracleでは、スキーマとユーザーは同じ。
ユーザー作成時は、CDBではなくPDBへ接続して作成する。
CREATE USER ユーザー名 IDENTIFIED BY パスワード;
(パスワードに引用符は必要無い)
このままだとログイン権限がないのでGRANTで権限を与える必要がある。
ユーザーに直接権限を与える
GRANT システム権限名 TO ユーザー名
[WITH ADMIN OPTION]
[IDENTIFIED BY パスワード] -- パスワードを変更する。
;
通常のアクセス権限はALL PRIVILEGESで与える。
GRANT ALL PRIVILEGES TO ユーザー名;
ロールを作成する
CREATE ROLE ロール名
[NOT IDENTIFIED | IDENTIFIED BY パスワード];
・[NOT IDENTIFIED]を指定することでパスワードを入力しなくてもロールを使用可能にする。
・[IDENTIFIED BY パスワード]ロールを使用するときに入力するパスワードを登録する。
ロールをユーザーに割り当てる
GRANT ロール名 TO ユーザ名;
主要な標準ロール名
CONNECT : 一般ユーザー用。DBへの接続と、参照と表の作成など。
RESOURCE : アプリ開発者用。プロシージャや関数やトリガー作成など。
DBA : DB管理者用。
EXP_FULL_DATABASE : エクスポート権限。
IMP_FULL_DATABASE : インポート権限。
RECOVERY_CATALOG_OWNER : リカバリカタログを扱う権限。
テーブルを作成する
CREATE文全般に「OR REPLACE」オプションを持つ。
CREATE文の「OR REPLACE」オプションは、既存のオブジェクトが既に存在したときに、オブジェクトを再作成する指令だ。
しかし、CREATE TABLE文には「OR REPLACE」オプションは存在しない。
CREATE OR REPLACE は、関数、プロシージャ、タイプ、ビュー、またはパッケージでのみ使用できる。
CREATE FUNCTION, CREATE LIBRARY, CREATE PACKAGE, CREATE PROCEDURE, CREATE TRIGGER, CREATE TYPE で使用可能。
最小 CREATE TABLE
CREATE TABLE テーブル名 (
列名1 型名 [オプション] ,
列名2 型名 [オプション] ,
列名N 型名 [オプション] ,
...
) ;
プライマリーキー1つ設定
CREATE TABLE テーブル名 (
列名1 型名 NOT NULL PRIMARY KEY ,
列名2 型名 [オプション] ,
列名N 型名 [オプション] ,
...
);
プライマリーキー2つ設定
CREATE TABLE テーブル名 (
列名1 型名 NOT NULL ,
列名2 型名 NOT NULL ,
列名N 型名 [オプション] ,
... ,
PRIMARY KEY( 列名1, 列名2 )
);
PRIMARY KEY宣言の前に、CONSTRAINTを指定することにより制約名を指定することができる。
CONSTRAINT 制約オブジェクト名 PRIMARY KEY( 列名1, 列名2 )
既存テーブルにプライマリーキーを設定
ALTER TABLE テーブル名 ADD PRIMARY KEY( 列名1, 列名2 ) ;
外部キー設定
CREATE TABLE テーブル名 (
列名1 型名 NOT NULL ,
列名2 型名 NOT NULL ,
列名N 型名 [オプション] ,
... ,
PRIMARY KEY( 列名1 )
FOREIGN KEY( 列名2 ) REFERENCES 外部テーブル名(列名2該当カラム名)
);
FOREIGN KEY宣言の前に、CONSTRAINTを指定することにより制約名を指定することができる。
CONSTRAINT 制約オブジェクト名 FOREIGN KEY( 列名2 ) REFERENCES 外部テーブル名(列名2該当カラム名)
後から追加するなら以下のようにする。
ALTER TABLE テーブル名 ADD CONSTRAINT 外部キー名;
ALTER TABLE テーブル名 ADD FOREIGN KEY (列名) REFERENCES 参照テーブル名(参照列名);
文字列データ型
CHAR, NCHARと、VARCHAR, VARCHAR2, NVARCHAR2 がある。
CHAR と NCHAR は、固定長文字列。代入した文字数が長さに満たない場合は、空白で埋める。
VARCHAR と VARCHAR2 と NVARCHAR2 は、可変長文字列。最大文字数は指定するが、それ以内の文字数であれば、自由な文字数の文字列を格納できる。
VARCHAR と VARCHAR2 の違いは、VARCHARは昔のバージョンで使用されていた文字列型で、VARCHAR2 が最新の文字列型。かつて文字を格納できる最大サイズが違っていた。今は、VARCHAR を宣言すると、内部で自動的に VARCHAR2 に変換するので、事実上 VARCHAR は既に存在しない。
NVARCHAR2 は、UTF-16が普及し始めたころに、それに対応する為に作られたデータ型で、データベースのキャラクターセットに関係無くUTF-16を使用する。
NVARCHAR2 はあるが NVARCHAR は存在しない。
NVARCHAR2 は、VARCHAR2 の UTF-16 版 として生まれたからだ。
文字エンコーディングについて
昔、日本語文字エンコーディングに Shift-JIS や EUC-JP を使用していたころ、キャラクターセットにはどの文字エンコーディングを使用するか、決まっていなかった。
CHAR と VARCHAR と VARCHAR2 は、データベースで設定されたキャラクターセットに従うので、これだけでは文字エンコーディングを特定できない。
しかし、現代ではキャラクターセットにはUTF-8を使用するのが、事実上の標準になっているので、CHAR と VARCHAR と VARCHAR2 は UTF-8 を使用すると考えて差し支えない。
NCHAR と NVARCHAR2 は、UTF-16 を使用するデータ型なので、キャラクターセットの影響は受けない。
つまり、事実上は UTF-8 のデータ型と UTF-16 のデータ型の二択となっている。
データ型の選択は、このどちらを使うかの選択となる。
UTF-8 と UTF-16 の違いは、使用するバイト数にある。UTF-8 は 1文字を 1バイトから 4バイトの可変長文字コードで表す。
UTF-16 は、1文字を 2バイトか 4バイトのどちらかで表す。
Unicode文字にはBMPと追加面の2種類の文字領域がある。追加面はサロゲートペアとも呼ばれる。
UTF-16実装の場合、BMPは必ず2バイトになる。追加面は必ず4バイトになる。
UTF-8実装の場合、BMPは1バイトから3バイトになる。追加面は3バイトか4バイトとなる。
CHAR と VARCHAR と VARCHAR2 はUTF-8を使用するので、英数字などは1バイトに治り、比較的データサイズが小さくなる。
データサイズが小さいと検索も更新も高速に実施できる。消費ストレージも少ない。
これに対し、漢字を使用する場合は3バイトか4バイトになり、データサイズが大きくなる。
データサイズが大きいと検索も更新も遅くなる。消費ストレージも大きい。
つまり、CHAR と VARCHAR と VARCHAR2 は、英数字をメインに使用するなら、高速な処理が期待できるが、漢字の特にサロゲートペアを使用する場合は、速度が遅くなる。
これに対し、NCHAR と NVARCHAR2 はUTF-16を使用するので、英数字の場合は常に2バイトを使用し、漢字を使用する場合は、BMPなら2バイトを、サロゲートペアなら4バイトを使用する。
つまり、漢字をメインに使用する場合は、NCHAR と NVARCHAR2を使用した方が、高速で動作することが期待できる。
UTF-8 と UTF-16 のどちらを使用するかは、データの文字に英数字をメインに使用するか、漢字の特にサロゲートペアをメインに使用するかによって使い分ける。
さらに正確に説明するとBMPをメインにするかサロゲートペアをメインにするかで使い分ける。
数値データ型
NUMBER、BINARY_FLOAT、BINARY_DOUBLEの三つで整数も実数も扱うことができる。
NUMBER型は、10進数の精度を保証した数値型で、シグネチャは以下の3種類ある。
NUMBER
NUMBER(精度値)
NUMBER(精度値 , スケール値)
精度値は、桁数のことで1から38までの数値を指定できる。
スケール値は、小数点以下の桁数のことで、-84から127まで指定できる。マイナス値の場合、例えば -1 なら1の位をゼロにすることができる。
金額などで1000円単位に丸める場合などに使用できる。
BINARY_FLOATは、32ビットの浮動小数点数。
BINARY_DOUBLEは、64ビットの浮動小数点数。
この両者は、10進数の精度保証は行なわない。内部の値は単純な2進数として扱う。
シグネチャはそのままである。
日時データ型
日付も時刻も通常は DATE型を使用する。
DATE型は1秒単位の時刻を記録できる。
1秒より細かい精度を必要とする場合は、TIMESTAMP型を使用する。
TIMESTAMP型は、10億分の1秒の精度の日時を記録する。
DATE型は7バイト、TIMESTAMP型は最大11バイト使用する。
シグネチャは、以下になる。
DATEはそのまま。
TIMESTAMP(精度値)
精度値は0から9になる。
大きな値ほど時刻の精度が高い。9なら10億分の1秒の精度になる。
0ならDATEと変わらない。
時差情報を持たせるTIMESTAMPもある。
TIMESTAMP WITH TIME ZONE は、単純に時差情報を持つTIMESTAMP型(13バイト)。
TIMESTAMP WITH LOCAL TIME ZONE は、 Oracleに設定したタイムゾーン情報に基づいて時差情報を持つTIMESTAMP型を定義する。(最大11バイト)
INTERVAL YEAR(精度値) TO MONTH は、年月の差分を格納するデータ型。
INTERVAL DAY(精度値) TO SECOND(精度値) は、日・時間・分・秒の差分を格納するデータ型。
精度値は0から9の値を指定できる。省略可能。
バイナリデータ型
RAW(バイト数)
LONG RAW 最大2GB
ラージオブジェクト型
CLOB キャラクターセットの文字エンコーディングのキャラクター・ラージオブジェクト
NCLOB UTF-16のキャラクター・ラージオブジェクト
BLOB バイナリ・ラージオブジェクト
ROWID(バイト数) BASE64文字列
BFILE バイナリファイル
ビューを作成する
CREATE OR REPLACE VIEW ビュー名 AS SELECT文;
インデックスを作成する
CREATE [UNIQUE | BITMAP] INDEX インデックス名
ON テーブル名(列名 [ASC|DESC],...)
[TABLESPACE 表領域名];
UNIQUE 通常のINDEXを作成する
BITMAP BITMAP INDEXを作成する
TABLESPACE INDEXを作成する表領域を指定する
ストアド・プロシージャを作成する
CREATE OR REPLACE PROCEDURE プロシージャ名(パラメータ名1 IN 型1, パラメータ名2 IN 型2, ...)
IS
宣言部;
BEGIN
処理部;
END;
/
パラメータの型名には、VARCHAR2(50)の(50)のようなサイズ指定は必要無い。
VARCHAR2 だけで良い。
宣言部と処理部は、行ごとに ; (セミコロン)で区切る。
宣言部にはサイズ指定が必要。
パラメータの宣言には、IN, OUT, IN OUTの指定が必要。
例:
CREATE OR REPLACE PROCEDURE sample_procedure(
p_id IN NUMBER,
p_name IN VARCHAR2,
p_age IN NUMBER
)
IS
BEGIN
INSERT INTO sample_table(id, name, age) VALUES(p_id, p_name, p_age);
END;
/
ストアド・ファンクションを作成する
CREATE [OR REPLACE] FUNCTION ファンクション名(引数 IN データ型[, ...])
RETURN 戻り値の型
IS
宣言部
BEGIN
処理部
END
;
/
パラメータの型名には、VARCHAR2(50)の(50)のようなサイズ指定は必要無い。
VARCHAR2 だけで良い。
RETURN の型名も同様。
宣言部と処理部は、行ごとに ; (セミコロン)で区切る。
宣言部にはサイズ指定が必要。
パラメータの宣言には、IN, OUT, IN OUTの指定が必要。
リテラル・代入・演算子
リテラル
文字列は単一引用符で囲む。二重引用符ではなく単一引用符である。
文字列中で単一引用符を使用する場合は、単一引用符を二つ続けて書く。
例: ’text’ , ‘I”m fine.’
変数
PROCEDUREやFUNCTIONのIS句の宣言部か、無名ブロックのDECLARE句の宣言部で、以下のように宣言する。
IS | DECLARE
変数名 := データ型 [NOT NULL] [{ := | DEFAULT } 値 ] ;
BEGIN
処理部
END
例:
w_COUNT NUMBER(9, 2) ;
w_NAME VARCHAR2(10) NOT NULL := 'TANAKA' ;
w_TELNO VARCHAR2(11) DEFAULT '01202532525' ;
代入
変数 := 値 | 計算式
例: A := 100 ;
演算子
加算 A + B
減算 A – B
乗算 A * B
除算 A / B
剰余 A % B
文字列連結 文字列A || 文字列B
「AがBより小さい」 A < B
「AはB以下」 A <= B
「AがBより大きい」 A > B
「AはB以上」 A >= B
「AとBは等しい」 A == B
「AとBは等しくない」 A != B または A <> B
文字列の比較も可能。
条件式やループなど
条件式
if else 相当
IF 条件式 THEN
処理
[ ELSEIF 条件式 THEN
処理 ]
[ ELSE
処理 ]
END IF;
switch相当
CASE 評価変数
WHEN 評価値 THEN 処理
[ WHEN 評価値 THEN 処理 ]
[ ELSE 処理 ]
END
CASE
WHEN 条件式 THEN 処理
[ WHEN 条件式 THEN 処理 ]
[ ELSE 処理 ]
END
ループ1
LOOP
処理
END LOOP;
ループの終了条件は無く、通常は EXIT と共に使用する。
ループ2
WHILE (条件式) LOOP
処理
END LOOP;
ループ3
FOR 変数名 IN [ REVERSE ] 開始値 .. 終了値 LOOP
処理
END LOOP;
ループ制御
break相当
EXIT [ ラベル名 ] [ WHEN 離脱条件式 ];
二重ループの場合、ラベル名を指定しないと、一番内側のループを離脱する。
外側のループのラベル名を指定すると、外側のループから離脱する。
WHEN 離脱条件式 を指定しなければ、無条件に離脱する。
continue相当
CONTINUE [ ラベル名 ] [ WHEN 離脱条件式 ];
使い方はEXITと同様。
CONTINUEはループから抜けずに、ループの先頭に戻り、次のループから継続する。
ストアドの例外処理の書き方
DECLARE句欄にEXCEPTION型で、例外名を定義する。
RAISE句で例外を作成する。
EXCEPTION句で、作成された例外を受け止める。
WHEN句で、例外名ごとの処理を振り分ける。
EXCEPTION句のRAISEで、例外を再作成する。
DECLARE
例外名 EXCEPTION;
BEGIN
処理;
RAISE 例外名;
EXCEPTION
WHEN 例外名 THEN
DBMS_OUTPUT.PUT_LINE ('指定の例外です。');
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE ('その他の例外です。');
RAISE -- 例外の再作成
END;
/
プロシージャや関数では、IS領域に、DECLARE領域の内容を書く。
カーソルの書き方
— DECLARE部でカーソルを宣言する。[ ] 表記は省略可能を意味する。
— BEGIN-END部で、カーソルをOPENして、FETCHで読み込み、最後にCLOSEする。
DECLARE
変数名 データ型;
CURSOR カーソル変数[(引数名 引数のデータ型 [:= 初期値])]
[RETURN 戻り値データ型] IS SELECT文 ;
BEGIN
OPEN カーソル変数[(引数)] ;
FETCH カーソル名 INTO 変数名 ;
CLOSE カーソル変数 ;
END;
— 複数行を読み込む場合に、FETCHを繰り返し呼び出す手段として、カーソルFORループがある。
FOR レコード名 IN カーソル変数 LOOP
END LOOP;
— または
FOR レコード名 IN カーソル変数(引数) LOOP
END LOOP;
FOR IN LOOP構文を使用するとカーソルのOPENもCLOSEもFETCHも書く必要が無い。FORのレコード名は他で定義する必要はない。
結果の参照をするときは、レコード名.列名 と書く。
— カーソル属性
カーソル%ISOPEN
カーソルがOPENされていればTRUE、そうでなければFALSEを返す。
カーソル%FOUND
FETCH後レコードを取得できたならTRUE、できなければFALSE、FETCH前ならNULLを返す。
カーソル%NOTFOUND
FETCH後レコードを取得できたならFALSE、できなければTRUE、FETCH前ならNULLを返す。
カーソル%ROWCOUNT
FETCHで取得したレコードの数を返す。
SQLの方言
コメントの書き方
/* 複数行コメント */
— 単一行コメント
SELECT文の方言
以下の省略形は推奨されていない。
left outer join
col1 = col2(+)
right outer join
col1(+) = col2
inner join
col1 = col2
full outer join
full outer join (省略形は存在しない)
INSERT文の方言
データだけを指定する
INSERT INTO テーブル名 VALUES ( ‘値1’ , ‘値2’ , ‘値3’ , ‘値4’ , ‘値5’ );
INSERT SELECT
INSERT INTO テーブル名 (列名1, 列名2, 列名3, 列名4)
SELECT 列名1, 列名2, 列名3, 列名4 FROM 参照テーブル名
UPDATE文の方言
インラインビューによる更新
UPDATE (インラインSELECT文) SET 列名1 = 値1 , 列名N = 値N
DELETE文の方言
インラインビューによる削除
DELETE FROM (インラインSELECT文) [WHERE句]
オブジェクトの存在確認の方法
テーブルの存在確認。
SELECT owner,table_name FROM dba_tables WHERE table_name = ‘テーブル名’;
オブジェクトの存在確認。
SELECT owner, object_name FROM dba_objects WHERE object_name = ‘オブジェクト名’ AND object_type = ‘オブジェクトタイプ’ ;
DBA_OBJECTS 以外にも 同一ユーザーのオブジェクトに限定するなら USER_OBJECTS も使用可能。owner 以外ならDBA_OBJECTS と同様のレイアウトになる。
トランザクションの使い方
トランザクションの開始
トランザクションは、最初の実行可能SQL文が検出された時点で開始されます。
実行可能SQL文は、DML文やDDL文、およびSET TRANSACTION文など、データベース・インスタンスへのコールを生成するSQL文のことです。
コミット
COMMIT
注意点としてコミットは自動では行なわれないので、全て手動でコミットしなければならない。
ロールバック
ROLLBACK

