
ITシステムの基礎知識を解説(IT素人さん向け)リンクリストに戻る
最初にお断りしておくがここで技術の話をするつもりはない。
このブログは非情技(非ITエンジニア)向けに記事を書いており、技術に近い話も「この概念は非情技の人にも役に立つのではないか」と思って解説している。
以前説明したパイプとキューの概念と同様に、スタックとLIFOという思考の道具について紹介したい。
スタックはキューとの対比で良く説明されるデータの受け渡し方法だ。
キューのFIFO(First In First Out)と逆で、
スタックはLIFO(Last In First Out)というロジックでデータを受け渡す。
キューはプロセス間通信の手段としてOSに実装されているが、スタックはプロセスそのもののメモリ管理手段として実装されている。
スタックがプロセス間通信の手段として使われることはない。
LIFO(Last In First Out)とは、ちょうど縦に長い箱の中に、上の穴から皿を一枚ずつ重ねて入れていく事に似ている。
箱の穴は上の穴だけなので、箱に入れた皿を取り出すには一番最後に入れた、上の皿から取り出すことになる。
この仕組みがLIFOである。
日本語では「後入れ先出し」と呼ぶ。
皿を一枚入れる事を「Push」と呼び、取り出すことを「Pop」と呼ぶ。
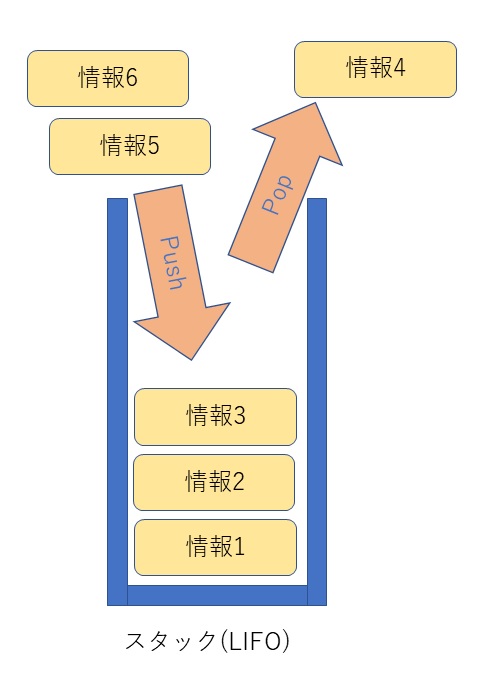
スタック(LIFO)では情報の入出力は以下のようになる。

情報1、情報2、情報3という順番に情報をスタックに入れると、最後に入れたものが一番上になる為、取り出すときは、情報3、情報2、情報1という順番に取り出すことになる。
古い情報が最も長く保存される。
新しい情報が最も先に取り出されることになる。
LIFOは何に使うのか
スタック(LIFO)は主にプロセス内のメモリ管理に使用する。
プロセスが起動時にOSによって与えられるメモリ空間は4種類ある。
静的メモリ領域(グローバル変数の格納)と動的メモリ領域(ヒープ)とスタック領域と命令(コード)領域である。
通常プログラマーはヒープとスタックとコード領域の三点セットで覚えている。
静的メモリ領域はヒープと区別していない人が多い。
(組み込みエンジニアはどうだか知らない。もっと詳しく理解していると思う)
ヒープについては後日解説する。
コード領域にはマシン語の命令の束が格納されている。
CPUにはプログラムカウンターという整数の記憶領域があり、ここに現在実行している命令の行番号(メモリのアドレス)が格納されている。
プログラムを実行するとプログラムカウンターの示す行番号の命令を実行し、終わるとプログラムカウンターの値をカウントアップ(1加算)する。
これを繰り返すことでプログラムを実行する。
現代のプログラムは一つの命令の束を順番に実行するのではなく「関数」と呼ばれる小さな命令の束に分割して、構成されている。
例えばプログラムのコード(命令の束)が以下のように構成されていたりする。
|
行番号1から9
|
main関数
|
|
行番号10から19
|
関数A
|
|
行番号20から29
|
関数B
|
|
行番号30から39
|
関数C
|
main関数が最初に呼び出される関数である。
これをエントリーポイントと呼ぶ。
main関数の中で、関数A、関数B、関数Cの順番に呼び出すのである。
|
行番号
|
命令
|
|
1
|
整数「I」をゼロに初期化
|
|
2
|
「関数A」を呼び出し 結果を「I」に加算する |
|
3
|
「関数B」を呼び出し
結果を「I」に加算する |
|
4
|
「関数C」を呼び出し
結果を「I」に加算する |
|
5
|
「I」を表示する
|
このようにする事で同じ処理は同じ関数を呼び出すことで、何度でも処理できるので、現代のプログラムはこのように関数に分けてモジュール分割されている。
モジュール分割には様々な手法が存在し、関数による分割が全てではない。
関数を呼び出すとプログラムカウンターの値を関数の先頭の行番号に書き換える。
「関数A」を呼び出すと、プログラムカウンターは「10」に書き換えられる。
関数を呼びだし処理が終了したら、元の行番号に戻さなければならない。
「関数A」が終わったら、プログラムカウンターは「19」になっているので、これを「3」に書き換えなければならない。
つまり関数の呼びだしは、呼ばれた行番号へ戻さなければならないのだ。
関数はどこから呼び出されるか分からない。
だから呼び出した行番号を覚えておかなくてはならない。
この関数呼び出し時に呼び出した行番号を覚えておく時にスタックが使われる。
上記の処理の場合、「関数A」を呼び出した時にスタックに「2」が保存(Push)される。
プログラムカウンターに「10」が書き込まれ「関数A」が実行される。
「関数A」の処理が終わったとき、スタックから「2」を取り出し(Pop)、プログラムカウンターに上書きする。
次はプログラムカウンターが「3」になり、「関数B」の呼出が行われる。
|
行番号
|
命令
|
スタックの内容
|
|
1
|
整数「I」をゼロに初期化
|
空
|
|
2
|
「関数A」を呼び出し
結果を「I」に加算する |
2
|
|
3
|
「関数B」を呼び出し
結果を「I」に加算する |
3
|
|
4
|
「関数C」を呼び出し
結果を「I」に加算する |
4
|
|
5
|
「I」を表示する
|
空
|
もし「関数A」の中で「関数B」が呼び出され、「関数B」の中で「関数C」が呼び出されていれば、どうなるか考えてみよう。
関数A
|
行番号
|
命令
|
|
10
|
整数「A」をゼロに初期化
|
|
11
|
「関数B」を呼び出し
結果を「A」に加算する |
|
12
|
「A」に「支店A」の売上を加算する
|
|
13
|
「A」を返す
|
関数B
|
行番号
|
命令
|
|
20
|
整数「B」をゼロに初期化
|
|
21
|
「関数C」を呼び出し
結果を「B」に加算する |
|
22
|
「B」に「支店B」の売上を加算する
|
|
23
|
「B」を返す
|
関数C
|
行番号
|
命令
|
|
30
|
整数「C」をゼロに初期化
|
|
31
|
「C」に「支店C」の売上を加算する
|
|
32
|
「C」を返す
|
この場合、スタックの内容は以下のように変位する。
|
行番号
|
命令
|
スタックの内容
|
|
1
|
整数「I」をゼロに初期化
|
空
|
|
2
|
「関数A」を呼び出し
結果を「I」に加算する |
2,11,21
|
|
3
|
「関数B」を呼び出し
結果を「I」に加算する |
3,21
|
|
4
|
「関数C」を呼び出し
結果を「I」に加算する |
4
|
|
5
|
「I」を表示する
|
空
|
「関数A」が呼び出されると、その中で「関数B」も呼び出される。
「関数A」の呼び元行番号を保持したまま、「関数B」の呼び元行番号も保存しなければならない。
「関数B」の中では「関数C」が呼び出されるので、「関数C」の呼び元行番号も保存しなければならない。
その保存内容が「2,11,21」となる。
関数Cから戻るときは行番号「21」が取り出されて戻り、
関数Bから関数Aへ戻るとき「11」が取り出されて戻り、
最後に「2」が取り出されて、main関数へ戻る。
スタックは関数呼び出しの呼び元行番号を保存するのに都合が良い。
「どこの誰が呼び出すが分からない」
「どこに戻るか呼び元によって違う」
などの時に、呼び元を効率良く記録しておくのに便利だ。
ローカル変数の保管領域にも使用する
元々は関数呼び出しの呼び元の保管に用意されたスタックという機能は、後にローカル変数の保管場所としても活用されるようになった。
「変数」というのはプロセスがOSから与えられた作業用メモリ空間の中に必要なサイズだけ固定的に領域を確保した作業領域のことだ。
例えば「整数」の値を保管しておくには8バイト(64bit)のサイズが必要になる。
作業用メモリ空間の中に8バイトの領域を確保してそこに適当な名前を付けた物が「変数」だ。
先ほどの「main関数」の行番号=1 に「整数 I をゼロに初期化」という処理があるが、この「I」が変数である。
この処理は作業メモリ上に8バイトの「I」という名前の領域を確保し、その領域に整数値「0」を上書き保管することを意味する。
先に、
「プロセスが起動時にOSによって与えられるメモリ空間は4種類ある。
静的メモリ領域(グローバル変数の格納)と動的メモリ領域(ヒープ)とスタック領域と命令(コード)領域である。」
と説明したと思う。
変数はこの全てのメモリ空間に確保できる。
但し、コード領域に確保した領域は値の内容を変更できない。
領域の変更もできない。
これは「定数」と呼ぶ。
静的メモリ領域に確保した領域はプロセス起動から終了まで、領域を変更できない。
(値の内容は自由に変更できる)
領域を自由に確保・解放できて、値も自由に書き換え可能な領域は、ヒープとスタック領域だけである。
ヒープ領域は大きな纏まった記憶領域を確保するには便利だが、多数の小さな変数の確保と解放を繰り返していると、領域が細かく分散してバラバラになってしまうフラグメンテーションという現象が起きてしまう。
フラグメンテーションが起きると速度の低下や合計領域は空いているのに領域を確保できなくなったりする。
ヒープについての解説は後日にする。
これらのヒープの問題を解消したのがスタック領域でのローカル変数の活用である。
ローカル変数は関数の中で関数が呼ばれたときにスタック領域に確保する変数だ。
LIFOでメモリを使用していくのでメモリの末端から順番に変数領域を確保していく。
関数は先に説明したように、関数A・関数B・関数Cというように累積的に呼び出される。
関数Aの使用する変数を「変数A」というように表せば、スタック領域に確保される変数は、「変数A、変数B、変数C」というように今使用する変数だけがスタックの端から確保されていく。
(先の関数A・関数B・関数Cの中の、整数「A」・整数「B」・整数「C」のこと)
関数が終了すると関数が使用している変数も解放される。
関数Cが終了すると変数Cが解放され、スタックの中身は「変数A、変数B」となる。
関数Bが終了すると変数Bが解放され、スタックの中身は「変数A」となる。
関数Aが終了すると変数Aが解放され、スタックの中身は「」となる。
新たに関数Bが呼ばれると、スタックの中身は「変数B」となる。
関数Bの中で関数Cが呼ばれると、スタックの中身は「変数B、変数C」となる。
関数Cが終了すると、スタックの中身は「変数B」となる。
関数Bが終了すると変数Bが解放され、スタックの中身は「」となる。
新たに関数Cが呼ばれると、スタックの中身は「変数C」となる。
関数Cが終了すると、スタックの中身は「」となる。
この話は正確にはmain関数の変数「I」もスタックに確保されるので、
スタックの中身には「変数I、変数A、変数B、変数C」のように、スタックの底にmain関数の変数が常に存在している。
このようにスタックを活用した変数領域の管理は非常に効率が良い。
今使用している変数の領域だけが確保でき使い終わったら解放して、メモリ領域の確保領域を必要最小限にしておける。
また、ヒープと違ってメモリの底から順番に領域を使用していくので、未使用領域は全て繋がった連続領域として空いており、空いている領域が使用できなくなることもない。
ローカル変数というものは非常に優れた発明なのだ。
ローカル変数と呼び元は同一のスタックに格納
ローカル変数と呼び元行番号は同一のスタックに格納される。
関数Aの中で、関数Bと関数Cが呼ばれた状態では、スタックの内容は以下のようになる。
(スタックは底から順番に領域を積み上げて行く)
|
動作内容
|
スタックの中身
|
|
整数「C」
|
|
|
関数C、起動
|
呼び元「21」
|
|
整数「B」
|
|
|
関数B、起動
|
呼び元「11」
|
|
整数「A」
|
|
|
関数A、起動
|
呼び元「2」
|
|
main関数、起動
|
整数「I」
|
関数Cが終了すると「呼び元21」と「整数C」は両方必要無くなるので、両方解放する。
関数Bが終了すると「呼び元11」と「整数B」は両方必要無くなるので、両方解放する。
このようにローカル変数と呼び元は、纏めて扱うと便利なので、同一のスタックで管理している。
LIFOの業務への応用
LIFOは要するに領域管理の方法論でもある。
現実世界でもこれを活用する場面はあると思う。
例えば在庫管理や倉庫の管理などに活用することはできないだろうか。
また特定の顧客に複数のサービスを提供する業務で、現在提供中のサービスの状態管理にLIFOを活用するなど。
例えば旅行ガイドなら、滞在ホテルの状態情報をLIFOに積み、滞在先のレストラン、観光施設、博物館など、の状態情報をLIFOに積み上げて管理する。
担当者が変更してもLIFOの中身を見れば一貫したサービスを提供できる。
(この場合LIFOは顧客ごとに別のを用意する)
非情技(非ITエンジニア)の方にはLIFO(スタック)の業務への活用を考えてみて欲しい。
情技師(ITエンジニア)に相談しても良いと思う。
