
クライアントからの接続先インスタンスの解説
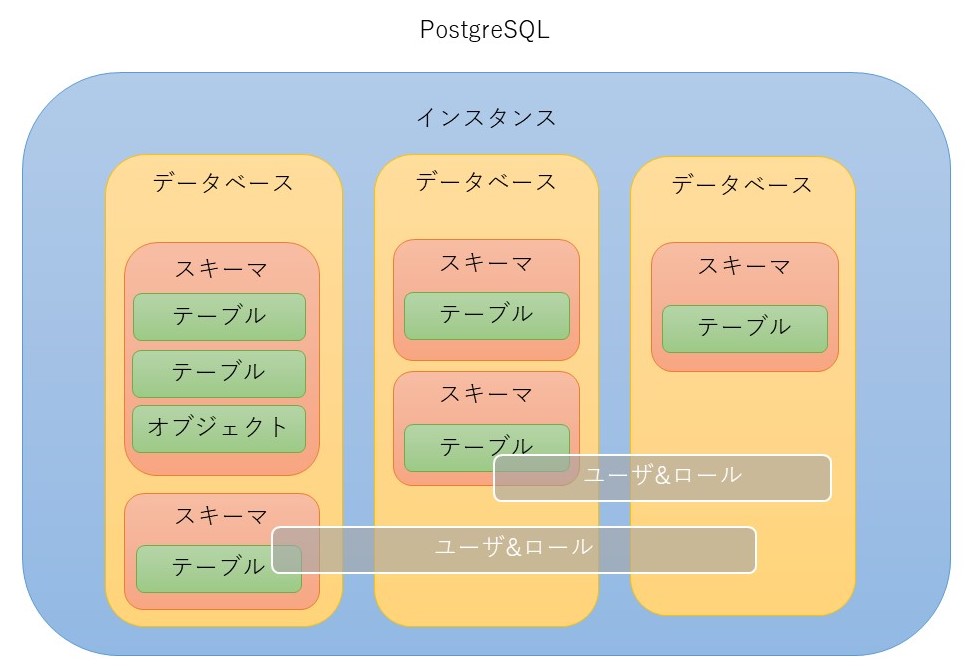
PostgreSQLは、原則として1サーバー1インスタンスで運用する想定だが、一つのサーバーに複数のインスタンスをインストールできる。
一つ一つのインスタンスは、別のバージョンでも良い。
しかし、インスタンスごとにポート番号は別々にする必要がある。この点はSQL Serverに似ている。
ログインはインスタンス単位に行なう。
SQL Serverと異なり、ログインするユーザーとデータベースを扱うユーザーは、同一である。
インスタンスの中に複数のデータベースを作成することができて、インスタンスにログインすると、権限さえあればインスタンス中の全データベースにアクセスできる。
ユーザーとロールは属性が違うだけで、同じモノである。
ユーザーとロールはインスタンスに紐付くので、複数のデータベースに跨がり使用することができる。
クライアントツール
コマンドラインツール
psql
GUIツール
pgAmin4
インスタンスへの接続・終了方法
コマンドラインツール
インスタンスへ接続する
psql -U ユーザー名
管理者権限はデフォルトで、postgres ユーザーが用意されている。
psql -U postgres によってログインすると全ての操作が可能になる。
終了方法
exit
データベースへの接続や切替
データベースへ接続する
psql -d データベース名
ユーザー名の指定も必要になるので、ユーザーとデータベースを指定することになる。
psql -U ユーザー名 -d データベース名
データベースを切替える
ログインしているものとする。
Windowsなら円マーク、LinuxやMacならバックスラッシュであることは、常識として説明する。
\c データベース名
または、
\connect データベース名
現在の確認
現在接続しているデータベースを確認する
select current_database();
または、
select current_catalog;
現在のスキーマを確認する
select current_schema;
現在のユーザーを確認する
select current_user;
一覧の表示
データベース一覧の表示
\l
スキーマ一覧の表示
\dn
または、
select schema_name from information_schema.schemata order by schema_name;
テーブル一覧の表示
\d
テーブルだけなら
\dt
ビューだけなら
\dv
オブジェクト一覧の表示
\d
これの後ろに付けるサブコマンドにより、
ユーザー一覧の表示
\du
または、
SELECT * FROM pg_user;
ロール一覧の表示
\dg
または、
SELECT rolname FROM pg_roles;
個別情報の表示
テーブルのレイアウトを表示する
\d テーブル名
ユーザーのロールを表示する
psqlの場合は、
\du
で、ログインしているユーザーのロールを確認する事ができる。
\du ユーザー名
で、指定ユーザーのロールを確認できる。 SQLで確認するなら、以下のように確認できる。
SELECT grantee, privilege_type
FROM information_schema.role_table_grants;
information_schema の、role_table_grantsビューには、ユーザーの権限情報がある。
SELECT grantee, privilege_type
FROM information_schema.role_table_grants
WHERE table_schema = 'スキーマ名'
AND table_name = 'テーブル名'
AND grantee = 'ユーザー名 or ロール名';
pg_rolesビューには、ロールに関する情報が格納されている。
SELECT r.rolname
FROM pg_roles r
JOIN pg_auth_members m ON r.oid = m.member
JOIN pg_roles g ON g.oid = m.roleid
WHERE g.rolname = 'ユーザー名';
ファイル入出力
SELECT結果をテキストファイルへエクスポートする
psqlで、テーブル内容をそのままCSVファイルへ出力する。OSユーザー側にフォルダーへのアクセス権限が必要。
Windowsの場合、PostgreSQLをインストールした「data」フォルダーなどにエクスポート可能。
COPY テーブル名 TO 'ファイルパス' WITH CSV DELIMITER ',';
SELECT結果をCSVファイルへ出力する。
psql -U ユーザー名 -d データベース名 -c "SQL文" -A -F',' > CSVファイル名
テキストファイルをインポートする
COPY テーブル名 FROM 'ファイルパス' DELIMITER ',' ;
OSユーザー側にフォルダーへのアクセス権限が必要。
Windowsの場合、PostgreSQLをインストールした「data」フォルダーなどが使用可能。
作成する
データベースを作成する
CREATE DATABASE データベース名 ENCODING 'UTF8' ;
文字エンコーディングは自由に指定できるが、UTF8が推奨される。
スキーマを作成する
CREATE SCHEMA [スキーマ名];
権限を与えるなら、
CREATE SCHEMA [スキーマ名] AUTHORIZATION [ロール名];
ユーザーを作成する
CREATE USER [ユーザー名] WITH PASSWORD 'パスワード';
データベース作成権限を与えるなら、
CREATE USER [ユーザー名] WITH PASSWORD 'パスワード' CREATEDB;
ユーザーに直接権限を与える
GRANT 権限 ON 対象 TO 誰に
通常必要になる操作権限を与える場合は、ALL PRIVILEGES 権限を与える。
GRANT ALL PRIVILEGES ON DATABASE データベース名 TO ユーザー名;
ユーザー名はロール名でも良い。
ALL PRIVILEGES は参照、更新、テーブルや関数やプロシージャの作成をする権限。
デーベース作成削除などの権限はない。
ロールを作成する
スーパーユーザーか、 CREATEROLE 権限を持っているユーザーのみ実行可能。
CREATE ROLE ロール名 ;
PosrgreSQLのロールはユーザーと同じものである。CREATE USER と CREATE ROLE の違いは、デフォルトで前者がログイン権限を持つのに対し、後者は以下の指定をしなければ、ログイン権限が与えられないだけである。
CREATE ROLE ロール名 WITH LOGIN PASSWORD 'パスワード';
よって、GRANT等の使い方もユーザーと同様である。
ロールにログイン権限を与えて使用する事は、通常ないと思うので、ロールはロールとして使用するのが妥当。
ロールをユーザーに割り当てる
GRANT ロール名 ON 対象オブジェクト TO 対象ユーザー ;
テーブルを作成する
最小 CREATE TABLE
CREATE TABLE [ IF NOT EXISTS ] テーブル名 (
列名 データ型名 [, ... ]
);
IF NOT EXISTS 指定は「対象テーブルが存在しないときだけ作成する」という意味で、省略可能。
プライマリーキー1つ設定
CREATE TABLE テーブル名 (
列名1 データ型名 PRIMARY KEY ,
列名2 データ型名 ,
....
) ;
プライマリーキー2つ設定
CREATE TABLE テーブル名 (
列名1 データ型名 ,
列名2 データ型名 ,
.... ,
PRIMARY KEY(列名1, 列名2, ...)
) ;
外部キー設定
CREATE TABLE [ IF NOT EXISTS ] テーブル名 (
列名 データ型名
[, ... ] ,
列名 データ型 REFERENCES 参照テーブル名 [(外部のキー列名 , ....)]
);
CREATE TABLE [ IF NOT EXISTS ] テーブル名 (
列名1 データ型名 ,
列名2 データ型名 ,
[ ... ] ,
FOREIGN KEY (列名1 , 列名2)
REFERENCES 参照テーブル名 [(外部のキー列名 , ....)]
);
文字列データ型
文字型はcharとvarcharとtextのみ。
ncharやnvarcharのようなUTF-16を使用する文字列型は存在しない。
char(文字数) 文字数指定無しなら、(1)と同じ。
varchar(文字数) 文字数指定無しなら、最大1GBまで格納できる。
text 最大1GBまで格納できる。
文字エンコーディングについて
文字型の対応する文字エンコーディングは多数あり、デフォルトで UTF-8 になっている。データベース単位でSJISやEUC-JPなどを指定することもできる。
テーブル単位やカラム単位の文字エンコーディング指定は不可能。
文字型の最大容量は1GB。
数値データ型
数値型はたくさんある。
整数
smallint 2バイト
integer 4バイト
bigint 8バイト
numeric(桁数, 位取り) 数値全体の有効桁数と、小数点以下桁数の二つの引数を指定する。
decimal numericと同じもの。
自動増分整数
smallserial 2バイト
serial 4バイト
bigserial 8バイト
実数
real 4バイト
double precision 8バイト
日時データ型
timestamp[(p)][without time zone] 日付時刻
timestamp[(p)] with time zone 日付時刻
date 日付のみ(時刻無し)4バイト
time[(p)] [wothout time zone] 時刻のみ 8バイト。
pは秒数の小数点以下桁数で0から6の範囲。
time[(p)] with time zone 時刻のみ 12バイト
interval [fields] [(p)] 時間間隔
fields の値は以下の種類がある。
YEAR
MONTH
DAY
HOUR
MINUTE
SECOND
YEAR TO MONTH
DAY TO HOUR
DAY TO MINUTE
DAY TO SECOND
HOUR TO MINUTE
HOUR TO SECOND
MINUTE TO SECOND
バイナリデータ型
bytes
ビューを作成する
CREATE OR REPLACE VIEW ビュー名 AS SELECT文;
インデックスを作成する
CREATE INDEX インデックス名 ON 対象テーブル名 (対象列名);
ストアド・プロシージャを作成する
ストアドプロシージャを記述できる言語は、たくさんある。
PL/pgSQL
PL/Perl
PL/Java
PL/R
PL/Python
PL/Python3
PL/pgSQL のみ説明する。
CREATE OR REPLACE PROCEDURE プロシージャ名(入出力指定子 変数名1 データ型 , 入出力指定子 変数名2 データ型 , ... )
LANGUAGE 'plpgsql'
AS $$
DECLARE
宣言部;
BEGIN
処理部;
EXCEPTION
例外処理部;
END
$$
パラメータの型名には、VARCHAR2(50)の(50)のようなサイズ指定は必要無い。
VARCHAR2 だけで良い。
パラメータの宣言には、入力以外は IN, OUT, INOUTの入出力指定子が必要。
OUT, INOUTの入出力指定子の使い方は簡単に説明できないので、ここでは説明しない。
宣言部と処理部は、行ごとに ; (セミコロン)で区切る。
宣言部にはサイズ指定が必要。
EXCEPTIONと例外処理部;は省略可能。
DECLARE・BEGIN・EXCEPTION・ENDのコード部分は、$$文字列$$ のように文字列リテラルで記述する必要がある。引用符も使用できるが、コード内で引用符が使用できなくなるので、通常は $$ を使用する。
プロシージャを呼び出すときは CALL を使用する。
CALL プロシージャ名(引数1, 引数2);
例:
---------------------------------------------------------------
-- PROCEDURE: public.dispname(bigint)
create or replace procedure public.dispname(in_aid bigint, in_animaltype varchar)
language 'plpgsql'
as $$
declare
scount int;
sword varchar(100);
begin
select name into sword from animals
where aid = in_aid and animatypes = in_animaltype;
raise notice 'name = %', sword;
end
$$;
実行方法は以下のようにする。
call public.dispname(2, 'cat');
ストアド・ファンクションを作成する
CREATE OR REPLACE FUNCTION 関数名(変数名1 データ型 , 変数名2 データ型 , ... )
RETURNS 返り値のデータ型
LANGUAGE 'plpgsql'
AS $$
DECLARE
宣言部;
BEGIN
処理部;
EXCEPTION
例外処理部;
END
$$
パラメータの型名には、VARCHAR2(50)の(50)のようなサイズ指定は必要無い。
VARCHAR2 だけで良い。
RETURN の型名も同様。
パラメータの宣言には、入力以外は IN, OUT, INOUTの入出力指定子が必要。
OUT, INOUTの入出力指定子の使い方は簡単に説明できないので、ここでは説明しない。
宣言部と処理部は、行ごとに ; (セミコロン)で区切る。
宣言部にはサイズ指定が必要。
関数では、引数に出力引数は使用できない。
EXCEPTIONと例外処理部;は省略可能。
DECLARE・BEGIN・EXCEPTION・ENDのコード部分は、$$文字列$$ のように文字列リテラルで記述する必要がある。
関数を呼び出す時は、SQL文の中で予備出す。
簡易的に呼び出すなら、以下のようにSELECT句の中で呼ぶ。
SELECT 関数名( 引数1, 引数2 ) ;
例:
---------------------------------------------------------------
-- FUNCTION: public.dispf(bigint)
create or replace function dispf(in_aid bigint)
returns varchar
language 'plpgsql'
as $$
declare
sword varchar(100);
begin
select name into sword from animals where aid = in_aid;
return sword;
end
$$
呼び出し方
select dispf(cast(1 as bigint));
リテラル・代入・演算子
リテラル
文字列は単一引用符で囲む。二重引用符ではなく単一引用符である。
文字列中で単一引用符を使用する場合は、単一引用符を二つ続けて書く。
例:
'text'
'I''m fine.'
ドル引用符文字列も使用できる。$ダグ名$で文字列を囲む。
$ダグ名$文字列$ダグ名$
タグ名は省略できるので、
$$文字列$$のように記述することもできる。
この表記法はプロシージャや関数のロジック記述にも使用している。
変数
PROCEDUREやFUNCTIONのDECLARE句の宣言部で、以下のように宣言する。
DECLARE
変数名 := データ型 [COLLATE 照合順序名] [NOT NULL] [{ := | = | DEFAULT } 値 ] ;
BEGIN
処理部
END
照合順序名には、データの文字列比較や並べ替えのときに、日本語か英語かなどロケールに合わせたソートや比較の基準を指定します。
“ja_JP.utf8” は日本語のUTF-8エンコーディングの照合順序名です。
例:
w_COUNT NUMBER(9, 2) ;
w_NAME VARCHAR2(10) NOT NULL := 'TANAKA' ;
w_TELNO VARCHAR2(11) DEFAULT '01202532525' ;
代入
変数 := 値 | 計算式
例: A := 100 ;
演算子
加算 A + B
減算 A – B
乗算 A * B
除算 A / B
剰余 A % B
文字列連結 文字列A + 文字列B
文字列連結代入 文字列A += 文字列B
「AがBより小さい」 A < B
「AはB以下」 A <= B
「AがBより大きい」 A > B
「AはB以上」 A >= B
「AとBは等しい」 A == B
「AとBは等しくない」 A != B または A <> B
文字列の比較も可能。
論理演算
AND , OR , NOT
条件式やループなど
条件式
if else 相当
IF 条件式 THEN
処理
[ ELSIF 条件式 THEN
処理
[ ELSIF 条件式 THEN
処理
...]]
[ ELSE
処理 ]
END IF;
switch相当
CASE 評価変数
WHEN 評価値1 [, 評価値2 [ ... ]] THEN
処理
[ WHEN 評価値M [, 評価値N [ ... ]] THEN
処理
... ]
[ ELSE
処理 ]
END CASE;
CASE
WHEN 条件式 THEN
処理
[ WHEN 条件式 THEN
処理
... ]
[ ELSE
処理 ]
END CASE;
ループ1
[ラベル名]
LOOP
処理
END LOOP;
ループの終了条件は無く、通常は EXIT と共に使用する。
例:
LOOP
EXIT WHEN count > 0;
END LOOP;
ループ2
[ラベル名]
WHILE 条件式 LOOP
処理
END LOOP;
ループ3
[ラベル名]
FOR 変数名 IN [ REVERSE ] 開始値 .. 終了値 LOOP
処理
END LOOP;
変数名の変数の値を、開始値から終了値まで繰り返す。
REVERSEを省略するとインクリメントする。
REVERSEを指定するとデクリメントする。
例:
FOR i IN 1..10 LOOP
-- 処理。
END LOOP;
FOR i IN REVERSE 10..1 LOOP
-- 処理。
END LOOP;
ループ4
[ラベル]
FOR レコード変数 | 行変数 IN SELECT文 LOOP
処理
END LOOP;
[ラベル]
FOR レコード変数 | 行変数 IN EXECUTE 動的コマンド文字列 LOOP
処理
END LOOP;
RECORD型で宣言しているレコード変数に、SELECT文の結果が返され、結果件数の回数だけループする。
レコード変数の代わりに、行変数を使用しても良い。
行変数は、テーブル名%ROWTYPE により宣言する。
SELECT文の代わりに動的コマンドを使用する事もできる。
最小限の解説なので、レコード変数と行変数と動的コマンドの解説はしない。
ループ制御
break相当
EXIT [ ラベル名 ] [ WHEN 離脱条件式 ];
二重ループの場合、ラベル名を指定しないと、一番内側のループを離脱する。
外側のループのラベル名を指定すると、外側のループから離脱する。
WHEN 離脱条件式 を指定しなければ、無条件に離脱する。
continue相当
CONTINUE [ ラベル名 ] [ WHEN 離脱条件式 ];
使い方はEXITと同様。
CONTINUEはループから抜けずに、ループの先頭に戻り、次のループから継続する。
ストアドの例外処理の書き方
PROCEDUREでもFUNCTIONでも、処理を記述するBEGINとENDの間に、EXCEPTIONを記述する。
例外発生時には、EXCEPTIONへジャンプする。
受け取った例外はWHEN句で分岐することができる。
全ての例外を受け取るなら WHEN OTHERS THEN を定義する。
基本構文 :
BEGIN
処理1;
処理N;
EXCEPTION
WHEN OTHERS THEN
例外処理
END;
独自の例外を発生させる場合は、RAISE句を使用する。
RAISE EXCEPTION USING ERRCODE = 'エラーコード', MESSAGE = 'エラーメッセージ' ;
基本構文2:
BEGIN
処理1;
RAISE EXCEPTION USING ERRCODE = '20100',MESSAGE = 'エラー発生';
処理N;
EXCEPTION
WHEN SQLSTATE '20100' THEN
RAISE INFO 'SQLSTATE = %', SQLSTATE;
RAISE INFO 'SQLERRM = %', SQLERRM;
WHEN OTHERS THEN
例外処理
END;
カーソルの書き方
-- DECLARE部でカーソル変数とレコード変数を宣言する。
DECLARE
カーソル変数 CURSOR FOR SELECT rec FROM tablename;
レコード変数 RECORD;
-- カーソルを開く
OPEN カーソル変数;
-- カーソルを読み込む
FETCH カーソル変数 INTO レコード変数;
-- カーソルを閉じる
CLOSE カーソル変数;
— カーソルループの書き方1
LOOP
FETCH カーソル変数 INTO レコード変数;
IF NOT FOUND THEN
EXIT;
END IF;
-- レコードを使用する処理。
END LOOP;
— カーソルループの書き方2
FOR レコード変数 IN カーソル変数 LOOP
-- レコードを使用する処理。
END LOOP;
SQLの方言
コメントの書き方
-- 行コメント
/* コメント開始
複数行コメント
コメント終わり */
SELECT文の方言
USING句による略記が可能。
USING (a, b, c)はON (t1.a = t2.a AND t1.b = t2.b AND t1.c = t2.c)と等価。
例 : (t1とt2の中にそれぞれnum列が存在する場合)
SELECT * FROM t1 INNER JOIN t2 USING(num);
INNER, LEFT, RIGHT, FULL いずれの結合でも使用可能。
INSERT文の方言
列指定を省略できる。
INSERT INTO テーブル名 VALUES (値1 , 値2 , …) ;
INSERT INTO テーブル名 SELECT 列名1, … 列名N FROM 参照テーブル名;
UPDATE文の方言
特に無し。
DELETE文の方言
特に無し。
オブジェクトの存在確認の方法
テーブルの場合は以下になる。
SELECT * FROM information_schema.tables WHERE table_name = 'table_name';
トランザクションの使い方
PostgreSQL ではトランザクションを構成するSQL コマンドを BEGIN と COMMIT で囲んで設定する。
トランザクションの開始
BEGIN
コミット
COMMIT
ロールバック
ROLLBACK

