
クライアントからの接続先インスタンスの解説
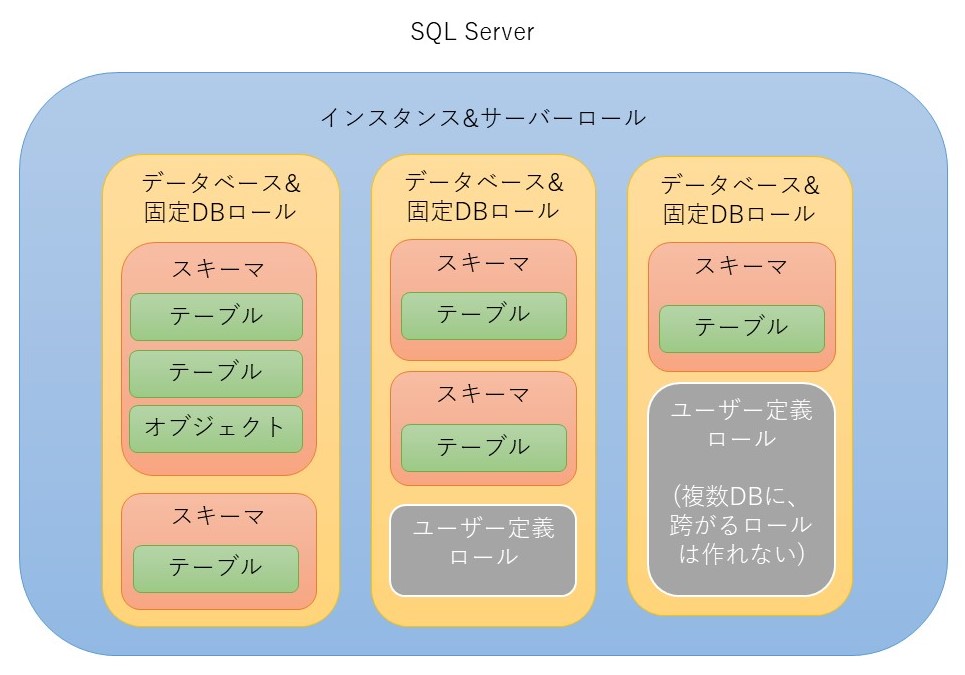
SQL Serverは、一つのサーバーの中に、複数のインスタンスを作成できる。
インスタンス自体がSQL Serverアプリの本体なので、インスタンス単位で異なるエディションやバージョンのSQL Serverアプリをインストールできる。
この場合、ポート番号はインスタンスごとに異なる物を割り当てる。
クライアントからの接続はインスタンス単位に接続する。
一つのインスタンスの中に複数のデータベースを作成出来る。
接続したインスタンス中のデータベースは、権限があれば全てアクセスできる。
データベースの中に複数のスキーマが作成できる。
インスタンスへのログイン用の(認証)ユーザーと、データベースの中で使用するユーザーは異なる。
SQL Serverではスキーマとユーザーは異なる。
初期ログインでは、dboスキーマにdboユーザーでログインする。両者のdboは異なるので注意。
クライアントツール
コマンドラインツール
sqlcmd (主流コマンドツールはこれ)
sqlps (旧ツール)
GUIツール
ssms (SQL Server Management Studio)
インスタンスへの接続・終了方法
コマンドラインツール
コマンドのパラメーターは以下の名称で表記する。
username = ユーザー名
password = パスワード
hostname = DBサーバーの名称
databasename = データベース名
SQL Server においては、ログイン認証用のユーザーは、DBの内部ユーザーとは別になる。
推奨設定でSQL Serverをインストールしている場合は、Windows認証になっており、Windowsのユーザーでログインする。
この場合、ログイン時にユーザー名やパスワードの入力は必要ない。
SQL Server認証でインストールしている場合は、sa ユーザーでログインする。パスワードはインストール時に決定しているはずである。
Linux版 SQL Serverは、SQL Server認証でインストールしている。
インスタンスへ接続する
SQL Server認証
sqlcmd -S localhost -U username -P password
Windows認証
sqlcmd -S localhost -E
終了方法
exit
データベースへの接続や切替
データベースへ接続する
ログイン時にデータベースも指定する。
SQL Server認証
sqlcmd -S server -U username -P password -d databasename
Windows認証
sqlcmd -S localhost -E -d databasename
データベースを切替える
use databasename;
現在の確認
現在接続しているデータベースを確認する
SELECT DB_NAME();
現在のスキーマを確認する
SELECT SCHEMA_NAME();
現在のユーザーを確認する
SELECT CURRENT_USER;
一覧の表示
データベース一覧の表示
SELECT NAME FROM SYS.DATABASES;
GO
スキーマ一覧の表示
SELECT CATALOG_NAME,SCHEMA_NAME,SCHEMA_OWNER
FROM データベース名.INFORMATION_SCHEMA.SCHEMATA;
SELECT * FROM SYS.SCHEMAS;
SELECT NAME FROM SYS.SCHEMAS ORDER BY NAME;
テーブル一覧の表示
SELECT NAME FROM SYSOBJECTS WHERE XTYPE = 'U' ;
オブジェクト一覧の表示
SELECT NAME FROM SYSOBJECTS;
ユーザー一覧の表示
先に説明したが、SQL Serverではログインユーザーと、データベースのユーザーは異なる。
ログインユーザー
SELECT NAME FROM SYS.SQL_LOGINS;
SELECT
NAME AS 'ログイン名',
TYPE_DESC AS '認証方法',
CREATE_DATE AS '作成日時',
MODIFY_DATE AS '更新日時'
FROM SYS.SERVER_PRINCIPALS
WHERE
TYPE IN ('S','U') AND
IS_DISABLED = 0
ORDER BY 更新日時 DESC;
データベースユーザー
SELECT * FROM SYSUSERS;
SELECT NAME FROM SYS.DATABASE_PRINCIPALS;
ロール一覧の表示
SELECT R.NAME, M.NAME
FROM SYS.DATABASE_ROLE_MEMBERS RM
LEFT OUTER JOIN SYS.DATABASE_PRINCIPALS R
ON RM.ROLE_PRINCIPAL_ID = R.PRINCIPAL_ID
LEFT OUTER JOIN SYS.DATABASE_PRINCIPALS M
ON RM.MEMBER_PRINCIPAL_ID = M.PRINCIPAL_ID;
個別情報の表示
テーブルのレイアウトを表示する
SELECT c.name,c.column_id FROM sys.columns AS c
INNER JOIN sys.tables AS t ON t.object_id = c.object_id
INNER JOIN sys.schemas AS s ON s.schema_id = t.schema_id
WHERE t.name = 'Users' AND s.name = 'dbo';
ユーザーのロールを表示する
SQL Serverでは、ユーザーとロールが明確に異なり、ロールはサーバーに紐付くものと、データベースに紐付くものが両方存在する。
以下の両方の一覧を表示するSQLを提示する。
サーバーロール
SELECT roles.principal_id AS RolePrincipalID
,roles.name AS RolePrincipalName
,server_role_members.member_principal_id AS MemberPrincipalID
,members.name AS MemberPrincipalName
FROM sys.server_role_members AS server_role_members
INNER JOIN sys.server_principals AS roles
ON server_role_members.role_principal_id = roles.principal_id
INNER JOIN sys.server_principals AS members
ON server_role_members.member_principal_id = members.principal_id
;
データベースロール
SELECT
USER_NAME(grantee_principal_id) AS ユーザー名,
class_desc AS クラス,
OBJECT_NAME(major_id) AS オブジェクト名,
permission_name as 権限名
FROM sys.database_permissions
WHERE grantee_principal_id = USER_ID('sampleDbRole') --ユーザー名 or ロール名を指定
ファイル入出力
SELECT結果をテキストファイルへエクスポートする
通常はBCPコマンドを用いてエクスポートとインポートを行なう。
BCPコマンドはテーブルのレイアウトに合わせてフォーマットファイルを作成し、そのフォーマットファイルをBCPコマンドに指定して、対象テーブルのエクスポートとインポートを行なう。
BCPコマンドの使い方を説明すると長くなるので、ここでは簡単なサンプルだけ記載する。
簡単エクスポート
コマンドラインに以下のコマンドを入力して実行する。
BCP テーブル名 out ファイル名 -c -T -t',' -S サーバーホスト名
テーブル名はピリオド区切りで、データベース名.スキーマ名.テーブル名 のように表記できる。
ファイル名は、パス名で指定する。相対パスでも絶対パスでも良い。
-c オプションは、文字データを文字列として出力する。
-T オプションは、Windows認証でログインする指定。
-t オプションは、カラムの区切り文字を指定する。省略するとタブ区切りになる。
-S オプションは、後ろに接続先のホスト名やIPアドレスを指定する。
例:
bcp [db].[dbo].[table1] out .\file1.csv -c -T -t',' -S localhost
簡単インポート
インポートの場合は、フォーマットファイルが必要になる。
最初に、BCPコマンドにフォーマットファイルを自動で作成させる。
BCP テーブル名 format nul -c -f フォーマットファイル名 -T -S サーバーホスト名
次に、作成したフォーマットファイルで、CSVファイルをインポートする。
BCP テーブル名 in ファイル名 -f フォーマットファイル名 -T -S サーバーホスト名
例:
bcp [db].[dbo].[test2] format nul -c -f .\test2_format.fmt -T -S localhost
bcp [db].[dbo].[test2] in .\test2.csv -f .\test2_format.fmt -T -S localhost
テキストファイルをインポートする
インポート手段には BULK INSERT を使用する方法もある。
BULK INSERT テーブル名
FROM '読み込みファイルのフルパス名'
WITH
(
FIELDTERMINATOR = ',' ,
ROWTERMINATOR = '\n'
);
例:
BULK INSERT [dbo].[test2]
FROM 'C:\test2.csv'
WITH (
FIELDTERMINATOR = ',', -- カンマ区切りの場合
ROWTERMINATOR = '\n', -- 行の終わりを示す文字(改行)を指定
FIRSTROW = 2 -- CSVファイルの最初の行はヘッダーなので、2行目から読み込む
);
作成する
データベースを作成する
CREATE DATABASE データベース名 COLLATE Japanese_CI_AS;
日本語への対応は、データベース単位で行うので、COLLATE(照合順序)で指定する。
日本語の照合順序は他にもいろいろ種類があるので、公式サイトで確認すること。
スキーマを作成する
CREATE SCHEMA スキーマ名 ;
SQL Serverでは、Oracleと違いユーザーとスキーマは全く異なる。
新規作成した場合は、dboスキーマがデフォルトで作成され、これを使用する事が多い。
dboスキーマと別に、dboユーザーも存在するので、混同しないように。
ユーザーを作成する
ログイン認証ユーザー
SSMSでサーバーを選択し、[セキュリティ] フォルダーを右クリックし、[新規作成] をポイントして、[ログイン]を選択するとログイン認証ユーザーを作成できる。
以下のSQLでも作成できる。
CREATE LOGIN ログインユーザー名
WITH
PASSWORD = 'パスワード',
DEFAULT_DATABASE = データベース名,
CHECK_EXPIRATION = OFF, -- 有効期限チェックしない
CHECK_POLICY = OFF -- パスワードの複雑性要件をチェックしない
;
GO
後でパスワードを変更する場合は、以下のようにする。
ALTER LOGIN ログインユーザー名
WITH
PASSWORD = '新パスワード'
;
GO
データベースユーザー
SSMSで[データベース]配下の特定データベースを選択し、その配下の[セキュリティ] フォルダーを右クリックし、 [新規作成] をポイントして、 [ユーザー] を選択します。
以下のSQLでも作成出来ます。
USE データベース名
GO
CREATE USER ユーザー名 FOR LOGIN ログインユーザー名 ;
GO
補足(認証方式)
SQL Server はログインセキュリティの設定方法として、「Windows認証」と「SQL Server認証」という二つの認証モードを有している。
Windowsの場合、最初にSQL Server をセットアップするとき、どちらを使用するか選択することになる。
自由にログインユーザー名を作成できるのは、「SQL Server認証」の方であり、デフォルトで管理者権限を持つ「sa」ログインユーザーが用意されている。
Linux版 SQL Server には「SQL Server認証」しか存在しない。
「Windows認証」の場合は、ログインユーザーにWindowsユーザーしか使用できない。
Windowsでユーザーを作成することになる。
ユーザーに直接権限を与える
他のDBMSのようにGRANTを使用して、権限を与えることもできる。
しかし、通常は固定データベースロールを割り当てる。
簡単に両方紹介する。
GRANTの使い方
[ ] 内は省略可能。
GRANT 権限名 [ ,...n ]
TO 対象名 [ ,...n ] [ WITH GRANT OPTION ]
[ AS 対象名 ]
「権限名」には SELECT, INSERT などの他に ALL [ PRIVILEGES ] がある。
「対象名」には以下の物が指定可能。
データベース・ユーザー
データベース・ロール
アプリケーション・ロール
Windows ユーザーにマップされたデータベース・ユーザー
Windows グループにマップされたデータベース・ユーザー
証明書にマップされたデータベース・ユーザー
非対称キーにマップされたデータベース・ユーザー
ログインできないデータヘース・ユーザー
固定データベースロールの使い方
SQL Server では、GRANTで個別に権限を与えるのではなく、予め用意された標準の固定ロールをユーザーに割り当てて、権限を与える。
固定の権限は、データベースに用意されている固定データベースロールと、インスタンス側に用意されている固定サーバーロールがある。
詳細は以下の公式解説を読んで欲しい。
これをちゃんと説明するとここでは、尺が足りないので、代表的な使い方だけ紹介するに留める。
固定データベースロールを使用するには、ALTER ROLE ~ ADD MEMBERを使用する。
ALTER ROLE 固定データベースロール ADD MEMBER データベースユーザー ;
例:
ALTER ROLE db_datareader ADD MEMBER appdbuser;
固定サーバーロールをログインユーザーに与えるときは、ALTER SERVER ROLE ~ ADD MEMBER を使用する。
ALTER SERVER ROLE 固定サーバーロール ADD MEMBER ログインユーザー名 ;
例:
ALTER SERVER ROLE sysadmin ADD MEMBER appuser;
補足(作成順)
SQL Server を使用するシステム開発を想定してみる。
システム管理者のユーザーと、アプリが使用するユーザーと、バックアップ担当ユーザーが、それぞれ必要になる。
システム管理者はDBMSの全ての機能が使えなければならないので、通常は「sa」などセットアップ時に使用した管理者ユーザーを使用する。
アプリが使用するユーザーは、DDLとDMLが使用できれば、他の権限は必要無い。
バックアップ担当ユーザーは、バックアップとリストアができればそれで良い。
それぞれ限定された権限を与える。
アプリが使用するユーザーを appuser と称して、固定データベースロールの使い方を紹介してみる。
SQL Server では、ログインユーザーとデータベースユーザーは別である。
SA権限(管理者の意味)でログインして、
最初にCREATE DATABASE で、データベース appdatabase を作成する。
次にログインユーザー appuser を作成する。
最後にデータベースユーザー appdbuser を作成する。
--ログインユーザー作成
CREATE LOGIN appuser WITH
PASSWORD = 'appuserp' ,
DEFAULT_DATABASE = appdatabase ,
CHECK_EXPIRATION = OFF ,
CHECK_POLICY = OFF ;
GO
--データベースユーザー作成
USE appdatabase ;
CREATE USER appdbuser FOR LOGIN appuser ;
GO
次にロールを割り当てる。ALTER ROLE ○○ ADD MEMBER △△; を使用する。
--読取り権限を与える
ALTER ROLE db_datareader ADD MEMBER appdbuser;
--更新権限を与える
ALTER ROLE db_datawriter ADD MEMBER appdbuser;
--作成権限を与える
ALTER ROLE db_ddladmin ADD MEMBER appdbuser;
db_datareader, db_datawriter, db_ddladmin は、固定データベースロールである。
これだけで、DMLとDDLが使用できるようになる。
バックアップリストアの権限を与えるのなら、db_backupoperator というロールが存在する。
他に、特定データベースの管理権限を与える db_owner というロールがある。
ちなみにSAユーザーが持つ全てを操作できる権限は、固定サーバーロールの sysadmin ロールで与える。
ALTER SERVER ROLE sysadmin ADD MEMBER appuser ;
以上の操作で、クライアントから appuser でログインして、appdatabase をDMLやDDLで操れるようになる。
なお、この場合、データベース appdatabase を操作しているデータベースユーザーは appdbuser となる。appdbuser 作成時に appuser と関連付けている。
ログインユーザーとデータベースユーザーは、関連付けをして使用する。
ロールを作成する
通常は固定ロールを使用するので、ロールは作成しない。
作成する場合は、サーバーロールとデータベースロールとアプリケーションロールで作り方は異なる。
サーバーロール
CREATE SERVER ROLE ロール名 [ AUTHORIZATION サーバー対象名 ]
ALTER SERVER ROLE diskadmin ADD MEMBER サーバー対象名 ;
データベースロール
CREATE ROLE ロール名 [ AUTHORIZATION オーナー名 ]
ALTER ROLE ロール名
{
ADD MEMBER 対象名
| DROP MEMBER 対象名
| WITH NAME = 新ロール名
}
[;]
アプリケーションロール
CREATE APPLICATION ROLE ロール名
WITH PASSWORD = 'パスワード'
, DEFAULT_SCHEMA = スキーマ名;
GO
ロールをユーザーに割り当てる
USE データベース名
GO
EXEC SP_ADDROLEMEMBER 'オーナー名', 'ユーザー名'
GO
テーブルを作成する
最小 CREATE TABLE
CREATE TABLE テーブル名 (
列名1 データ型 パラメータ ,
列名2 データ型 パラメータ ,
... ,
列名N データ型 パラメータ
) ;
GO
プライマリーキー1つ設定
CREATE TABLE テーブル名 (
列名1 データ型 PRIMARY KEY ,
列名2 データ型 ,
列名N データ型
) ;
GO
プライマリーキー2つ設定
CREATE TABLE テーブル名 (
列名1 データ型 パラメータ ,
列名2 データ型 パラメータ ,
... ,
列名N データ型 パラメータ ,
PRIMARY KEY ( 列名1 , 列名2 )
) ;
GO
後からキーを追加する場合。
ALTER TABLE テーブル名 ALTER COLUMN 列名 型名 NOT NULL;
ALTER TABLE テーブル名 ADD PRIMARY KEY (列名);
外部キー設定
CREATE TABLE テーブル名 (
列名1 データ型 パラメータ ,
列名2 データ型 パラメータ ,
... ,
列名N データ型 パラメータ ,
PRIMARY KEY ( 列名1 ),
FOREIGN KEY (列名2)
REFERENCES 外部対象テーブル名(対象テーブルの列名2)
) ;
GO
後から外部キーを追加する場合。
ALTER TABLE テーブル名
ADD FOREIGN KEY (外部キー列名)
REFERENCES 外部対象テーブル名(外部キー列名);
文字列データ型
キャラクターセットに従う文字列型
char[(n)] 固定サイズ文字列。最大8000文字。
varchar[(n)] 可変サイズ文字列。最大2GB。
text 最大2GBの文字列。
UTF-16文字列型
nchar[(n)] 固定サイズUTF-16文字列。最大4000文字。
nvarchar[(n)] 可変サイズUTF-16文字列。最大2GB。
ntext 最大2GBのUTF-16文字列。
文字エンコーディングについて
データベース、テーブル、カラムの単位でそれぞれ照合順序を定義できる。
照合順序とは、ソートロジックの様なもので、文字列を比較照合するとき「平仮名と片仮名を区別するか」「英文字の大文字小文字を区別するか」など照合基準を選べるようになっている。
SQL Serverでは照合順序セットが多数用意されており、テーブル単位カラム単位でCOLLATE句により照合順序セットを指定することができる。
文字列にはcharとnchar、varcharと nvarcharがある。
charとvarcharは文字エンコーディングが自由で通常はUTF-8を使用する。最大文字数は8千字。
ncharとnvarcharは無条件にUTF-16を使用する。最大文字数は4千字。
どちらもUnicodeのSCが有効な照合順序を指定すると、SCを含む全てのUnicode文字が使用可能になる。SCが無効な照合順序を指定すると、BMPだけ使用可能になる。
両者の使い分けで重要なのは、「UTF-8とUTF-16のどちらを使うか」「SCは必要か」「高速の検索や置換は必要か」の視点。
varcharとnvarcharでは、SCを含まない照合順序の場合は、varcharの方が早く、SCを含む照合順序の場合は、nvarcharが早い。
SCは、UTF-8の場合、SCは複雑で長い文字コードになるが、UTF-16の場合は、4バイト固定なので早くなる。
数値データ型
SQL Server は数値型が多い。
10進数保証しているものを真数、浮動小数点数を概数と呼ぶ。
真数型
bigint -2^63 から 2^63-1の範囲で、8バイト消費する。
int -2^31 から 2^31-1の範囲で、4バイト消費する。
smallint -32,768 ~ 32,767の範囲で、2バイト消費する。
tinyint 0 ~ 255の範囲で、1バイト消費する。
decimal -10^38 +1 ~ 10^38 – 1の範囲で、最大17バイト消費する。
numeric decimal型と同じ。
decimal と numeric は、p(最大桁数)とs(小数点以下有効桁数)を指定できる。
decimal(p [, s] ) [, s] は省略可能。numericでも同様。桁指定自体が省略可能。
桁数指定次第で消費バイト数は変わる。
money -922,337,203,685,477.5808 ~ 922,337,203,685,477.5807の範囲で、8バイト消費する。
smallmoney -214,748.3648 ~ 214,748.3647の範囲で、最大4バイト消費する。
概数型
float 最大8バイトの浮動小数点数。仮数部のビット数を指定可能。例、float(n) 。
real 最大4バイトの浮動小数点数
日時データ型
date 0001-01-01 ~ 9999-12-31
smalldatetime 1900-01-01 から 2079-06-06と 00:00:00 から 23:59:59
datetime 1753年1月1日~ 9999年12月31日と00:00:00 から 23:59:59.997。値は、.000、.003、または .007 秒単位に丸められる。
datetime2 1 月 1 日 1 CE ~12 月 31 日 9999 CEと00:00:00 から 23:59:59.9999999。精度は100 ナノ秒。
datetimeoffset 1 月 1 日 1 CE ~12 月 31 日 9999 CEと00:00:00 から 23:59:59.9999999。精度は100 ナノ秒。タイム ゾーンのオフセット範囲 -14:00 ~ +14:00で時差情報を有する。
time 00:00:00.0000000 ~ 23:59:59.9999999の範囲。精度は100 ナノ秒。
バイナリデータ型
binary [(n)] n バイトの固定長バイナリデータ。n は 1 から 8,000 の範囲内。
varbinary [(n)] 可変長のバイナリデータ。n は 1 から 8,000 の範囲内。
varbinary(max) 可変長のバイナリデータ。
image 0 ~ 2^31-1 (2,147,483,647) バイトの可変長のバイナリ データ。
ビューを作成する
CREATE VIEW ビュー名 AS SELECT文;
インデックスを作成する
SQL Serverでは、指定キーの順番にデータを並び替えるインデックスをクラスター化インデックスと呼ぶ。これはテーブルと別の索引情報を持たない。
索引情報を別に持つインデックスは、非クラスター化インデックスと呼ぶ。
プライマリーキー指定は自動的にクラスター化インデックスになる。
UNIQUE制約もクラスター化インデックスになる。
非クラスター化インデックス
CREATE INDEX index1 ON schema1.table1 (column1);
クラスター化インデックス
CREATE CLUSTERED INDEX index1 ON database1.schema1.table1 (column1);
UNIQUE制約付き非クラスター化インデックス
CREATE UNIQUE INDEX index1
ON schema1.table1 (column1 DESC, column2 ASC, column3 DESC);
ストアド・プロシージャを作成する
–基本構文
CREATE PROCEDURE ストアドプロシージャ名
@引数名1 データ型 ,
@引数名2 データ型 [ OUTPUT ] -- 出力引数ならOUTPUTを付ける。
AS
BEGIN
DECLARE @ローカル変数名 データ型名; --ローカル変数なら
[ 処理 ]
END
GO
実行するときは、EXECUTE または EXEC を使用する。
DECLARE @変数名 データ型名;
EXECUTE ストアドプロシージャ名 @引数名1 = 引数1値 , @引数名2 = @変数名 OUTPUT
または、
EXEC ストアドプロシージャ名 引数1値 , @引数名2 = @変数名 OUTPUT
例:
USE AdventureWorks2012;
GO
CREATE PROCEDURE HumanResources.uspGetEmployeesTest2
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
GO
実行方法
EXECUTE HumanResources.uspGetEmployeesTest2 N'Ackerman', N'Pilar';
GO
— Or
EXEC HumanResources.uspGetEmployeesTest2 @LastName = N'Ackerman', @FirstName = N'Pilar';
GO
— Or
EXECUTE HumanResources.uspGetEmployeesTest2 @FirstName = N'Pilar', @LastName = N'Ackerman';
GO
ストアド・ファンクションを作成する
CREATE FUNCTION 関数名 ( @引数名1 データ型名, @引数名2 データ型名 )
RETURNS データ型名
AS
BEGIN
DECLARE @ローカル変数名 データ型名;
[ 処理 ]
-- 例→ SELECT @ローカル変数名 = 列名 FROM テーブル名 WHERE ...
RETURN @ローカル変数名;
END
GO
実行するときは、SELECT文などで呼び出す。
SELECT 関数名 ( @引数名1 = 引数1値 , @引数名2 = 引数2値 ) ;
または、
SELECT 関数名 ( 引数1値 , 引数2値 ) ;
リテラル・代入・演算子
リテラル
文字列リテラルは単一引用符で文字列を囲む。二重引用符は QUOTED_IDENTIFIER オプションが OFF の時だけ使用可能になる。単一引用符が推奨される。
単一引用符をリテラル中に使用する場合は、単一引用符を二つ続けて記述する。
例: ‘Mojiretsu’ , ‘O”Brien’
Unicode文字列の場合は、先頭にNを、続けて単一引用符で文字列を囲む。
例: N’Mojiretsu’
数値リテラルとして、末尾にLを付けるとlong 型数値リテラルとなり、末尾にUを付けると符号なし数値リテラルとなる。末尾にEを付けると指数となる。
例: 123L , 456U
変数
変数名は@で始まる。DECLARE句で変数を宣言する。
DECLARE @変数名 データ型 [ = 初期値 ] ;
変数宣言をカンマで区切って、複数宣言することもできる。
例:
DECLARE @RowCounter INT;
DECLARE @Max INT , @Min INT ;
DECLARE @AllCounter INT = 0 ;
代入
代入は SET句を使用する。
SET @変数名 = 値 ;
SELECT結果を変数に代入するには、以下の様に書く。
SELECT @変数名1 = 列名1 , @変数名2 = 列名2 FROM テーブル名 ;
演算子
加算 A + B
減算 A – B
乗算 A * B
除算 A / B
剰余 A % B
文字列連結 文字列A + 文字列B
文字列連結代入 文字列A += 文字列B
「AがBより小さい」 A < B
「AはB以下」 A <= B
「AがBより大きい」 A > B
「AはB以上」 A >= B
「AとBは等しい」 A == B
「AとBは等しくない」 A != B または A <> B
文字列の比較も可能。
論理演算
AND , OR , NOT
条件式やループなど
条件式
if else 相当
IF 条件式
処理
[ ELSE
処理 ]
SQL Server には ELSEIF 構文は無い。
しかし、IF文のネストは存在するので、ELSE IF と記述することは可能。
例:
IF 条件1
BEGIN
処理1
END
ELSE IF 条件2
BEGIN
処理2
END
ELSE
BEGIN
処理3
END
このような ELSE IF の記述は可能である。
この場合、ELSEの中にネストする形で副IF文が定義されている。
見た目はELSEIFと変わりない。
最後のELSEは、副IF文のELSEである。
switch相当
CASE 評価変数
WHEN 評価値 THEN 処理
[ WHEN 評価値 THEN 処理 ]
[ ELSE 処理 ]
END
CASE
WHEN 条件式 THEN 処理
[ WHEN 条件式 THEN 処理 ]
[ ELSE 処理 ]
END
ループ1
WHILE 条件式
BEGIN
処理
END
ループ2
SQL Server のループは WHILE句 だけです。
ループ制御
break相当
BREAK;
continue相当
CONTINUE;
ストアドの例外処理の書き方
BEGIN TRYからEND TRYの中に主処理を書き、
例外が発生した場合の処理は、BEGIN CATCHからEND CATCHの中に書く。
BEGIN TRY
[主処理]
END TRY
BEGIN CATCH
[例外処理]
END CATCH
[ ; ]
例外を発生させる場合は、THROWを実行する。
THROW [ エラー番号 , エラーメッセージ , 状態 ] [ ; ]
エラー番号 :
例外を表す定数または変数です。 エラー番号 は int で、50000 以上、2147483647 以下にする必要がある。
エラーメッセージ :
例外を説明する文字列または変数。 エラーメッセージは nvarchar(2048)
状態 :
メッセージに関連付けられる状態を示す、0 から 255 の範囲の定数または変数です。 状態 は tinyint です。
例:
THROW 51000, 'レコードは存在しません。', 1 ;
明確なエラー例外を発生させたい場合は、RAISERRORを実行する。
RAISERROR ( { メッセージID | メッセージ文字列 | @変数 }
{ , 重大度レベル , 状態 }
[ , メッセージパラメーター [ , ...n ] ] )
[ WITH オプション [ , ...n ] ]
メッセージID : ユーザー定義エラー メッセージのエラー番号は、必ず 50000 より大きくなります。
メッセージ文字列 : ユーザー定義メッセージ。最大 2,047 文字。
@変数 : メッセージ文字列 と同じ形式の文字列を含む有効な文字データ型の変数。
@変数 は、char または varchar であるか、これらのデータ型に暗黙的に変換できるデータ型である必要がある。
重大度レベル : このメッセージに関連付けられたユーザー定義重大度レベル。
重大度レベル 19 から 25 までは、WITH LOG オプションを必要とする。
0 より小さい重大度レベルは 0 と解釈される。
25 より大きい重大度レベルは 25 と解釈される。
状態 : 0 ~ 255 の整数、一意の値を使用すると、コードのどのセクションでエラーが発生しているのかを楽に探すことができる。
メッセージパラメーター : メッセージ文字列 で定義された変数、または メッセージID に対応するメッセージの書式引数に使用されるパラメーター。
オプション : エラーのカスタム オプション。LOG、NOWAIT、SETERROR の三つ。
LOGは、エラー ログとアプリケーション ログにエラーを記録する。
NOWAITは、クライアントにすぐにメッセージを送信する。
SETERRORは、重大度レベルとは無関係に、@@ERROR 値と ERROR_NUMBER 値に メッセージID または 50000 を設定する。
例:
RAISERROR ('エラー。', 16, 1);
カーソルの書き方
-- カーソル変数とレコード変数を宣言する。
DECLARE @カーソル変数 CURSOR ;
DECLARE @レコード変数 データ型 ;
-- カーソル変数へSELECT文を関連付ける。
SET @カーソル変数 = CURSOR FOR SELECT文 ;
-- カーソル宣言とSELECTと関連付けを一度にすることもできる。
DECLARE @カーソル変数 CURSOR FOR SELECT rec FROM tablename ;
-- カーソルを開く
OPEN @カーソル変数 ;
-- カーソルを読み込む
FETCH NEXT FROM @カーソル変数 INTO @レコード変数 ;
-- カーソルを閉じる。
CLOSE @カーソル変数 ;
-- カーソルのリソースを開放する。
DEALLOCATE @カーソル変数 ;
— カーソル状態(FETCHの直後に@@FETCH_STATUSの値を確認して、終了やエラーを判定する)
@@FETCH_STATUS INTEGERT型で、以下の値を返す。
0 : FETCHは正常に実行した。
-1 : FETCHはエラーかレコード変数を溢れた。
-2 : FETCHで読み込むレコードが無い。
-3 : FETCHを実行しない。
通常は、以下のようにWHILE文でFETCHを繰り返す。
DECLARE @cur CURSOR FOR SELECT a, b, c FROM tablename;
OPEN @cur ;
FETCH NEXT FROM @cur ;
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM @cur ;
END
CLOSE @cur ;
DEALLOCATE @cur ;
SQLの方言
コメントの書き方
-- text_of_comment
/*
text_of_comment
*/
SELECT文の方言
INNER JOIN に関しては以下の省略記法が使用できる。
select * from dbo.Users u, dbo.Groups g
where u.GroupId = g.GroupId ;
昔、OUTER JOINに関しても += または =+ によって省略記法が使用できたが、現在は使用できない。
JOINの省略記法は推奨されないので、INNER JOIN, LEFT JOIN, RIGHT JOIN など、標準SQLでの記法で記述することがお勧めです。
INSERT文の方言
カラム名の省略ができる。
INSERT INTO テーブル名 VALUES(‘カラム値1’ , ‘カラム値2’ , ‘カラム値3’ , ….);
SELECT結果をINSERTする。
INSERT INTO テーブル名 SELECT * FROM 参照テーブル名;
UPDATE文の方言
特に無し。
DELETE文の方言
特に無し。
オブジェクトの存在確認の方法
IF OBJECT_ID (N'テーブル名', N'U') IS NOT NULL
有り (テーブルが存在するときの処理)
ELSE
無し (テーブルが存在しないときの処理)
OBJECT_IDの第一引数の「テーブル名」は「オブジェクト名」でも良い。
第二引数は以下のようにオブジェクトの種類を示す。
AF = 集計関数 (CLR)
C = CHECK 制約
D = DEFAULT (制約またはスタンドアロン)
F = FOREIGN KEY 制約
FN = SQL スカラー関数
FS = アセンブリ (CLR) スカラー関数
FT = アセンブリ (CLR) テーブル値関数
IF = SQL インライン テーブル値関数
IT = 内部テーブル
P = SQL ストアド プロシージャ
PC = アセンブリ (CLR) ストアド プロシージャ
PG = プラン ガイド
PK = PRIMARY KEY 制約
R = ルール (旧スタイル、スタンドアロン)
RF = レプリケーション フィルター プロシージャ
S = システム ベース テーブル
SN = シノニム
SO = シーケンス オブジェクト
U = テーブル (ユーザー定義)
V = ビュー
トランザクションの使い方
トランザクションの開始は、「BEGIN TRANSACTION」を宣言するだけ。
終了も以下の通りである。
トランザクションの開始
BEGIN TRANSACTION
コミット
COMMIT TRANSACTION
ロールバック
ROLLBACK TRANSACTION

